



Developers Diary 2
11 Jun 2020Have you ever watched a team of five-year-olds play soccer? The way the mass of children chases the ball around in a group? I think programmers do that too.

There’s something about working on a problem together that is so much more rewarding than working separately, we cannot help but get drawn into other peoples problems. There’s a lot of gratification to be had in finding a solution to a shared difficulty!
Even better, different people bring different perspectives to a problem, and illuminate different areas of improvement.
Maximum Inscribed Circle
A couple months ago, my colleague Martin Davis committed a pair of new routines into JTS, to calculate the largest circles that can fit inside a polygon or in a collection of geometries.
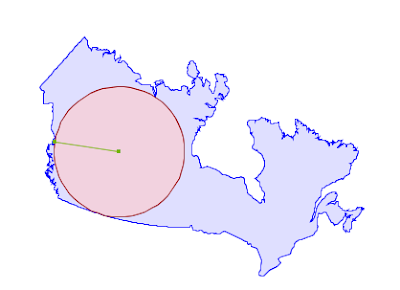
We want to bring all the algorithmic goodness of JTS to PostGIS, so I took up the first step, and ported “maximum inscribed circle” to GEOS and to PostGIS.
When I ported the GEOS test cases, I turned up some odd performance problems. The calculation seemed to be taking inordinately long for larger inputs. What was going on?
The “maximum inscribed circle” algorithm leans heavily on a routine called IndexedFacetDistance to calculate distances between polygon boundaries and candidate circle-centers while converging on the “maximum inscribed circle”. If that routine is slow, the whole algorithm will be slow.
Dan Baston, who originally ported the “IndexedFacetDistance” class got interested and started looking at some test cases of his own.
He found he could improve his old implementation using better memory management that he’d learned in the meantime. He also found some short-circuits to envelope distance calculation that improved performance quite a bit.
In fact, they improved performance so much that Martin ported them back to JTS, where he found that for some cases he could log a 10x performance in distance calculations.
There’s something alchemical about the whole thing.
- There was a bunch of long-standing code nobody was looking at.
- I ported an unrelated algorithm which exercised that code.
- I wrote a test case and reported some profiling information.
- Other folks with more knowledge were intrigued.
- They fed their knowledge back and forth and developed more tests.
- Improvements were found that made everything faster.
I did nothing except shine a light in a dark hole, and everyone else got very excited and things happened.
Toast Caching Redux
In a similar vein, as I described in my last diary entry, a long-standing performance issue in PostGIS was the repeated reading of large geometries during spatial joins.
Much of the problem was solved by dropping a very small “TOAST cache” into the process by which PostGIS reads geometries in functions frequently used in spatial joins.

I was so happy with the improvement the TOAST cache provided that I just stopped. Fortunately, my fellow PostGIS community member Raúl Marín was more stubborn.
Having seen my commit of the TOAST cache, and having done some work in other caching parts of PostGIS, he took up the challenge and integrated the TOAST cache with the existing index caches.
The integrated system now uses TOAST identifiers to note identical repeated inputs and avoid both unneccessary reads off disk and unncessary cache checks of the index cache.
The result is that, for spatial joins over large objects, PostGIS 3.1 will be as much as 60x faster than the performance in PostGIS 3.0.
I prepared a demo for a bid proposal this week and found that an example query that took 800ms on my laptop took a full minute on the beefy 16-core demo server. What had I done wrong? Ah! My laptop is running the latest PostGIS code (which will become 3.1) while the cloud server was running PostGIS 2.4. Mystery solved!
Port, Port, Port
I may have mentioned that I’m not a very good programmer.
My current task is definitely exercising my imposter syndrome: porting Martin’s new overlay code from JTS to GEOS.
I knew it would take a long time, and I knew it would be a challenge; but knowing and experiencing are quite different things.
The challenges, as I’ve experienced them are:
- Moving from Java’s garbage collected memory model to C++’s managed memory model means that I have to understand the object life-cycle which is implicit in Java and make it explicit in C++, all while avoiding accidentally introducing a lot of memory churn and data copying into the GEOS port. Porting isn’t a simple matter of transcribing and papering over syntactic idiom, it involves first understanding the actual JTS algorithms.
- The age of the GEOS code base, and number of contributors over time, mean that there are a huge number of different patterns to potentially follow in trying to make a “consistent” port to GEOS. Porting isn’t a matter of blank-slate implementation of the JTS code – the ported GEOS code has to slot into the existing GEOS layout. So I have to spend a lot of time learning how previous implementations chose to handle life cycles and call patterns (pass reference, or pointer? yes. Return value? or void return and output parameter? also yes.)
- My lack of C++ idiom means I spend an excessive amount of time looking up core functions and methods associated with them. This is the only place I’ve felt myself measurably get better over the past weeks.
I’m still only just getting started, having ported some core data structures, and little pieces of dependencies that the overlay needs. The reward will be a hugely improved overlay code for GEOS and thus PostGIS, but I anticipate the debugging stage of the port will take quite a while, even when the code is largely complete.
Wish me luck, I’m going to need it!
If you would like to test the new JTS overlay code, it resides on this branch.
If you would like to watch me suffer as I work on the port, the GEOS branch is here.