10 Feb 2007
Not a geospatial post, but… I fired up my home accounting software today, to get caught up in preparation for tax time, and look what greeted me:
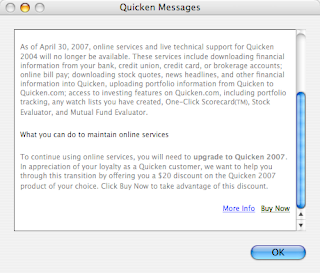
Intuit is going to shut down all the internet services associated with my copy of Quicken for Mac. But good news! I can upgrade to Quicken 2007 for only $50 and keep my services! Yay!
Holy corporate screwings, Batman! Nice way to drive the upgrade process, Intuit, but a little tough on the customer loyalty — I feel like a beast being driven over Head Smashed In Buffalo Jump. Gotta make those quarterly numbers.
Time to research alternatives — deeds like this should not go unpunished.
06 Feb 2007
This aught to be fun! I just typed “foss4g” into Google:
http://www.google.com/search?q=foss4g
And as of now (February 5, 2007), FOSS4G2007 is on the first search page, near the bottom, which is good but not terrific. FOSS4G2006 is #1, which is not surprising. In the middle we have some interesting stuff, like highly regarded blogs that have mentioned FOSS4G recently, or not.
It will be fun to watch the 2007 event climb the page as the buzz grows, month by month!
05 Feb 2007
I have not said much about it, blog-wise, but one of the big things I am doing this year is chairing the FOSS4G 2007 conference, which will be in Victoria from September 24-27.
We got off to a late start (compared to most conferences), only getting official approval at the end of 2006, so January 2007 was really the start of organizing. I decided to spend the first month concentrating on sponsorship, since so many other decisions are dependent on available resources — knowing how much sponsorship is available is really helpful. It has been a great month! We are going to meet our budget targets for sure, and maybe substantially exceed them.
Committed sponsors so far are:
-
Platinum
-
Gold
- Google
- Refractions
- DM Solutions
- BC Integrated Land Management Bureau
- Safe Software
-
Silver
- Pacific Alliance Technologies
- Open Geospatial Consortium
- City of Nanaimo
And there are more in the pipeline!
Today the Call for Workshops went out too, which marks the start of our program activities. We have already confirmed Damian Conway as our keynote speaker – an excellent speaker on open source topics, I am really looking forward to that talk.
Unfortunately the web site does not yet reflect some of the cooler things we have planned for the conference this year:
-
Integration’o’rama
- A live integration demonstration on the exhibition hall floor, exhibitors will have the opportunity to show their products interacting with products from other exhibitors in real time! Refractions will provide a PostGIS database instance, full of data from BC ILMB, which web mapping servers will render, and desktop apps will edit, and web frameworks will provide wrapped access to, and so on and so on. Unlike proprietary vendors, open source vendors have to interoperate, because no one has a complete stack to sell.
-
Demonstration Theatre
- More conventional, but a first for FOSS4G. Since we have a real show floor, we can have a real demonstration theatre and get exhibitors and projects to show their software strutting its stuff on the big screen.
-
Friday Code Sprint
- At the end of the conference we will be retaining some space and internet connectivity so that projects can get together in one room and plan or hack or just talk for an extended period. The internet is great, but face-to-face is the highest bandwidth connection available.
Last year, 535 people came to Lausanne for FOSS4G2006 (including me!). It was a great event, but far away from the USA and Canada. It has now been over two years since a North American open source geo-spatial get together (last time was Minnesota in June 2005).
So much has happened since then!
Autodesk has joined the community, Mapguide is going great guns, slippy maps have transformed web mapping, the desktop apps are all making huge strides, PostGIS has been OGC certified, Oracle has started buying open source companies…
It is a new world, and FOSS4G 2007 is going to be the place to take the pulse of that new world.
04 Jan 2007
I considered taking my chances and breaking the chain after being tagged by Sean, but you have to respect someone who is willing to publicly expose himself as an unabashed wine snob, so here goes:
- As a three year old, while riding on the back of my mother’s bike, I jammed my foot into the spokes of the back wheel, because she refused to stop and play at the swings we were passing. It should come as no surprise to you that I remember the moment vividly.
- I make an excellent pie crust. Everybody says so.
- For two years in graduate school, I spent an inordinate amount of time mucking about on a “multi-user simulated environment” called TrekMUSE. (What is it about graduate school and high octane time wasting?) Amazingly, it is still online. (
telnet tos.tos.net 1701)
- In kindergarten, my teacher asked me what my favourite color was. I said “yellow”. I am pretty sure I was right.
- I recently spent 12 months taking care of my daughter full time, between her first and second birthday. It was an experience I strongly recommend to all dads.
Being a merciful soul, I will tag… noone.
11 Dec 2006
Having talked about Oracle’s client licensing which is “freely redistributable within the bounds of certain definitions of the word ‘free’”, I wondered about ESRI’s client licensing.
The ESRI SDE client Java libraries are not publicly downloadable, at least not explicitly. You can physically get your hands on them by downloading a service pack and pulling them out of there. For whatever reason, there is no click through license and no license included in the service packs, so those who live by the letter of the law might feel fine just using them as found.
Those of us living by the spirit of the law need to go one level deeper. We have an ESRI Developer Network package, so I pulled out the SDE developer kit disk and installed the Java clients. The license I had to agree to in that process did not say anything specific about the client libraries, so I assume they are covered in the general license, which is pretty explicit:
Licensee shall not redistribute the Software, in whole or in part, including, but not limited to, extensions, components, or DLLs without the prior written approval of ESRI as set forth in an appropriate redistribution license agreement.
Looks like black-letter law to me.
Like Oracle, ESRI is missing out on an opportunity to grow an ecosystem of dependent open source client applications. As Howard Butler points out in a comment, proprietary companies like LizardTech let open source projects ship their SDK clients with their builds. It’s called market building.



