26 Nov 2016
Long live NRPP!
The Natural Resource Permitting Project (NRPP) is now mired down, having failed to deliver on its ambitious promises to transform the sector with “generic frameworks that will support the ‘One Project, One Process’ model”.
But, as my ‘ole grand-pappy used to say to me: “When the going gets tough, the tough redefine success so they can still declare victory.”

Accordingly, success re-definition is under way at NRPP. Success will no longer be a generational transformation in how government manages natural resources; success will now be submitting formerly paper forms using web forms.
But wait, I said NRPP is “mired down”, how can I tell? By measuring the outputs against the inputs.
Lots of Money Going In
NRPP has been ongoing in various forms and names since before 2013, and for at least the last two years has been carrying a staff/consultant complement that I’d estimate costs about $17M per year. I’ve heard estimates of expenditures to date of over $50M, and that is consistent with my back-of-the-envelope calculations.
So, $50M or more in. What’s come out? (Worth remembering, successful $1B start-up companies have been built for less.)
Not So Much Coming Out
In March of 2016, the Executive Director of NRPP gave a progress update to the Deputy Ministers Committee on Transformation and Technology (DMCTT). Good news: “year 2 of the initiative has been delivered on time, on scope and on budget”.
- Clients can now access NRS online services for guidance, information and map-based data to support applications for authorizations
- 290 data layers are now accessible through NRS Online Services
- Hunters will be able to register online for the Limited Entry Hunt in mid-April 2016
- Legislation will be introduced in Spring 2016 to move selected Fish and Wildlife authorizations to a criteria based notification model
All of these assertions are superficially true, but even from my perch far outside the warm light of the inner circles of government, it’s laughably easy to find substantial caveats and concerns about all four of them.
I really wonder what the is purpose of reporting to high-level “oversight” committees like DMCTT, if the committees just accept the reports and do not bother to do any independent verification and research.
If you have only the information and spin from the project in front of you, no matter how piercing and direct your analysis is, you’re never going to really be able to ask the tough questions, because the key information will be hidden or obfuscated.
This is why so much “oversight” seems to devolve into reductive discussions of schedule and budget, the only metrics that all participants are guaranteed to understand and that all projects are required to provide.
Feel free to deliver a product that fails to meet your user needs – the big boss will never notice. But slip your schedule by 2 weeks, and the fiery wrath of God will descend upon you. Project management and communication is optimized accordingly.
NRPP “Achievements”
I want to look closely at each of the pieces of good news about “year 2”.
Let’s do this interactively: go find the NRS online services web site. I’ll wait. Use the Google, start from the Ministry web site, however you like, go to it.
Back? How did it go?
I’ll wager you didn’t find the actual Natural Resource Sector Online Services portal, which though online seems to be linked to from nowhere, outside or inside the BC government.
This puts the claim that “clients can now access NRS online services” a little in doubt. Sure, they “can” access the services, but since the services are basically hidden, do they access the online services?
This new portal is one of the products of the $50M spent so far. It has an “OK” design, a bit wasteful of screen real estate and bandwidth, but clean and not too “last century”.
The portal also has a bunch of content and links to existing processes, which would be more impressive if they were not duplicative of content and links already assembled and put on the web (in the last decade) by Front Counter BC.
The $50M folks at NRPP appear to have mostly taken the content from Front Counter BC and re-skinned it using their modern web design, but provided vanishingly little value beyond that.
Re-packaging existing in-house knowledge and claiming it for your own is an old consultant trick from way, way back. Mark Twain once joked that “an expert is anyone who comes from more than 60 miles away”, and little seems to have changed since his time.
290 data layers are now accessible through NRS Online Services
Indeed they are, at least quite a few layers, I didn’t bother to count. However, like the portal, the mapping application is a recapitulation of functionality that government has been providing for a decade. Way back in 2002, the “Ministry of Sustainable Resource Management” was tasked to “deliver a corporate land and resource information data warehouse”: that is, a collection of all the land information in BC, and a web view of those layers. The warehouse and web maps have been around in various forms ever since.
In many technical respects the NRS map is superior to the old ImapBC (it’s more modular and reusable) but for the purposes of this post note that (a) like the portal it’s carefully hidden from public view and (b) it’s still not a net-new gain of functionality on a project that’s $50,000,000 in.
Hunters will be able to register online for the Limited Entry Hunt in mid-April 2016
Again, this is true, but yet again there’s less there than meets the eye. NRS was going to transform resource tenuring: one account for all users; new modern and modular technology; change the way the land base is managed.
None of that has happened here.
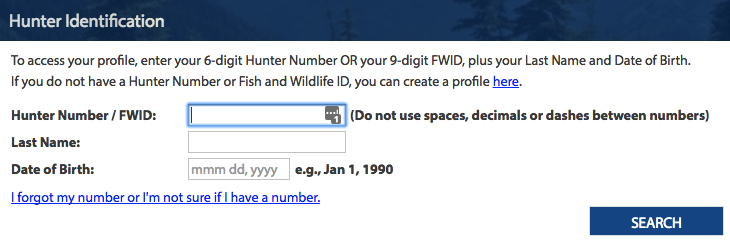
I took the app for a test drive (not so far as applying for a license, though maybe I should have) and what stuck out for me is:
- The business process is basically “paper form on the web”. You still need a special “Hunter Number” to apply – the business process clearly hasn’t been transformed at all, nor integrated into a “one process” framework.
- Technologically, if you peel back the web code and look underneath, the whole thing is being managed by a system called “POSSE”.
Why is it significant that POSSE is being used to manage this web form? Because POSSE is the system used by, wait for it… Front Counter BC! The same folks NRS cadged their portal content from.
So the “new” Limited Entry Hunt app has the same smell as the portal itself. Finding themselves unable to meet their stated goals of business transformation and new technology, NRPP is now building Potemkin deliverables using old business process and old technology.
Of course, having met one deliverable by giving up on “transformation” and just stuffing existing business process into web forms, what are the odds that NRPP will go on to do the same for the whole portfolio and then declare “victory”? Very high, very high indeed.
Legislation will be introduced in Spring 2016 to move selected Fish and Wildlife authorizations to a criteria based notification model
This was the only promise not tied to technology deliveries, and sadly it looks like it perished at the hands of a government too tired out to pass substantive legislation. I searched the Hansard for the spring 2016 session and did not find any evidence that the legislation was introduced.
Recap
On one side of the ledger:
On the other side of the ledger:
- A “portal” nobody can find, full of content other people assembled.
- A map nobody can find, full of content that has been accessible for a decade.
- An app built on old technology using the same old business process.
- Legislation that was not introduced.
Here are the things we cannot blame this on:
- Stupid people
- Bad intentions
- Political shenanigans
- Graft or corruption
Here are the things we can blame this on:
- Excessive size and ambition of the project
- Elevation of process over product
NRPP was/is a mistake. It’ll deliver something, in the end, but that something won’t be worth 10% of the money that is spent to achieve it. Hopefully NRPP is the last of the “transformation” projects to come out of government, and future business process improvement/integration efforts can evolve incrementally over time, at 10% of the cost and 10% of the risk.
22 Nov 2016
I frequently write things that people in the government IT community probably find hurtful. I do it deliberately, because I think the issues should be aired.
As I semi-jokingly tell my family, with reference to my former career as a government IT consultant: “I want to make sure I never work in this town again.”
At this point, I’m pretty sure that I have succeeded.
Bill Tieleman has a very even-handed write-up on the troubling rush of journalists into the BC Liberal Party’s tent over the past few years.
In fact, Tieleman’s take is so even-handed it displays the same fault that he’s bending over backwards to not describe: he’s avoiding saying hurtful things in order to retain future relationships.
But the question isn’t whether Darling or Johal were biased toward the BC Liberals. It’s how much their years of hard-earned fairness will help their new party sell some dubious claims — even about issues the two journalists may have ripped them on in the past.
Tieleman is a communications expert with a professional interest in remaining a respected member of the club of communications experts, and he very carefully avoids impugning the motivations of any of the subjects of this article, while larding out praise for his subjects’ “hard-earned fairness”.
Similarly, journalists have a professional interest in maintaining good relationships with their fellow professionals, the communications and PR staff (and their bosses) in the organzations they report on.
Why would they not?
The exit ramps of journalism are few and far between: corporate PR, and government communications. For a very few well-known press celebrities, like Jas Johal or Steve Darling, perhaps a direct leap to politics (with a winning party, if you still want a pay-cheque, n’est pas).
In these tenuous times, it is perhaps too much to ask, but I’d like my journalism to come from folks who aren’t so chummy with the people they report on. And I don’t just mean “I’d like a job later” chummy. I also mean “we’re all just blokes doing a job together” chummy. The kind of chummy that leads to events like the Press Gallery dinners in Ottawa and the Correspondents Association Dinner in DC, where the press and their subjects mingle and share comedy stylings and even the most egregious policy decisions can be played for a joke (remember George W. Bush looking for WMDs in a “hilarious” bit from 2004).
I don’t think many journalists write the stories that will never let them work in this town again.
In fairness, not many of them can afford to. It’s probably not a coincidence that some of the harshest takes on BC government policy and politics come from journalists and professionals who are safely retired.
Precarious employment has a way of disciplining folks, no matter if they are blue collar mill workers or white collar journalists: you’ve got to go along to get along.
It used to be that free speech only belonged to those who owned a printing press. Now it belongs to those beyond the reach of the marketplace: are you secure enough not to care what anyone thinks of you? Write away. Otherwise: you know the party line, stick close to it.
14 Nov 2016
For the past year, I have been fighting a running battle with my body. The battlefields have been my wrists and back. By and large, my body has been winning.
When sports commentators talk about a player “playing with pain” I think it’s natural to think about the pain in the moment – that play, that sprint, that quick turn on the grass, the game on the line. What doesn’t get talked about is the psychological effect of the pain, day after day, on the player. At practice, at home, at rest. How it changes their relationship to the game.
They love the game. Clearly. It’s what they’ve spent their whole life perfecting. But now, every interaction with it is colored by the overlay of pain. Do your warm-ups, work through that early pain, now feel the pain on each play. Good play or bad, it doesn’t matter. It hurts to do the thing.
No matter how much you love something, if you are given a negative stimulus every time you do it, you’ll stop liking it so much. This isn’t psychological weakness, it’s just conditioning. It’s how we train pets; how we try to stop smoking.
I used to take up my work every morning with enthusiasm. Now I take it up because I must, my enthusiasm is very attenuated. And I cannot figure it out for sure: am I not liking the work, is my ennui related to the actual tasks; or have I been conditioned, slowly but surely, to not like it? It’s very hard to tease those apart, because the conditioning works so very deep down in the stack of consciousness, and I’ve been playing with the pain for what feels like forever. I can’t remember what it was like before, anymore.
Anyways, I have a good chair. I’ve gotten a better keyboard and mouse. I ice my wrists every night. Sometimes things are better, sometimes they are worse, but drip, drip, drip, the reinforcement is mostly negative.
I’m only 300 words in, and it hurts.
I’ll stop now. Experience with repetitive strain, magic solutions? Hit the comments. Unfortunately, the only thing that has worked for me so far is not using computers.
04 Nov 2016
Update: A commenter the proponent estimated a plant power usage of 1,500,000 MWh / year, which is three times larger than my guesstimate. The EAO document notes it is a very conservative (large) estimate, but at the outside it would imply a subsidy three times larger – about $45,000,000 per year compared to the old LNG power pricing deal. It’s probably somewhere between.
The British Columbia government’s new “eDrive” rate for LNG producers is going to be creating new jobs at an ongoing cost of $138,000 per job at the electrically powered Woodfibre LNG plant in Squamish.

Let’s do the math, shall we? Here’s the input data:
Now the math:
- 2,100,000 tonnes of LNG times
- 230 kWh of electricty is
- 483,000,000 kWh per year of useage. Which can also be stated as
- 483,000 MWh per year. Times
- $28.68 per MWh in eDrive subsidy equals
- $13,852,440 per year in foregone revenue for BC Hydro, which for
- 100 permanent jobs is
- $138,524 per job
If we want to create 100 new government-funded jobs:
- Why are we paying $138,524 for each of them; and,
- Why are they freezing methane, and not teaching kids or building transit or training new engineers.
Government is about choices, and this government is making some batshit crazy choices.
02 Nov 2016
The CloudBC initiative to “facilitate the successful adoption of cloud computing services in the British Columbia public sector” is now a little over a year old, and is up to no good.

Like any good spawn of enterprise IT culture, CloudBC’s first impulse has been to set themselves up as the arbiter of cloud vendors in BC, with a dedicated revenue stream for themselves to ensure their ongoing hegemony.
The eligibility request currently online1 for CloudBC is a master-work of institutional over-reach:
- Only CloudBC approved services2 can be sold to the BC public sector.
- Approved services will add an ‘administration fee’ to all their billing3 to the BC public sector and remit that fee to CloudBC.
- The fee4 will be 2%.
And in exchange for that 2% of all cloud services, CloudBC will provide what in return?
Well, they’ll set the eligibility list, so the BC public sector will be literally paying for someone to tell them “no”. Setting the list will include a few useful services like FOIPPA reviews and making the vendors cough up promises to follow various international standards that nobody reads and few people audit. So that’s something. But mostly just more reasons to say “no”.
I misspent some hours reviewing the agendas [Part-1, Part-2] of CloudBC for the its first year in operation, and among the interesting tidbits are:
- The request to vendors was supposed to be released in October 2015, but was actually released in fall of 2016.
- Negotiations with Microsoft for Office 365 and what was dubbed the “Microsoft opportunity” were started in summer of 2016, but shut down in spring of 2016: “decision to communicate that CCIO5 will not pursue the deal as presented by Microsoft”
- Taking the website live was targeted for June 2016, but as of writing it remains “under construction”.
- Spring 2016 plans include contracting with a vendor for a “CloudBC digital platform”, so we’ll at least have an expensive under-utilized web presence “soon” (no RFP exists on BC Bid).
- CloudBC was budgeted $1.6M for year one, and managed to under-spend by about 20%. Getting almost nothing done has it’s benefits!
- An office and several staff have been seconded, so from an institutional existence point-of-view, CloudBC is off to a roaring start.
When I first heard about CloudBC, I was pretty excited. I naïvely thought that the mandate might include promoting, for example, cloud infrastructure inside BC.
Our FOIPPA Act requires that personal information of BC citizens not be stored outside the jurisdiction or by foreign-controlled corporations. That makes using cloud services (usually hosted outside BC, usually owned by foreign corporations) a hard lift for government agencies.
Wouldn’t it be nice if someone did something about that? Yes it would. cough
While setting up “private cloud” infrastructure is anathema (it’s very hard to find success stories, and all signs point to public cloud as the final best solution) in BC there are some strong incentives to take the risk of supporting made-in-Canada clouds:
- Thanks to FOIPPA, the alternative to made-in-BC cloud is no almost no cloud at all. Only apps with no personal information in them can go on the US-owned public clouds, which is a sad subset of what government runs.
- There are other jurisdictions and other technology domains that need non-US sourced cloud infrastructure. Seeding a Canadian-owned-and-operated PaaS/IaaS cloud industry would open the door to that marketplace.
“Just” getting the FOIPPA Act changed would be the cheapest, “simplest” solution (ignoring the humungous, intense, non-negotiable, insuperable political issues). Since that’s unlikely to occur, the alternative is DIY. I thought CloudBC might be that initiative, but turns out it’s just another enterprise IT control-freak play.
- Search for ON-002797
- “As only Eligible Customers with a written agreement in effect with the Province will be permitted to use the procurement vehicle established by this Invitation, including the CloudBC Marketplace, the Province intends to establish and maintain a list of Eligible Customers on the CloudBC Marketplace for use by Eligible Cloud Providers.”
- “CloudBC Framework Agreements will appoint and require the Eligible Cloud Provider to collect and remit as agent an incremental Administration Fee to be paid by Eligible Customers with Contracts in order to fund the CloudBC operations administered by the Province.”
- “An amount equal to 2% of the fees for all services provided”
- BC Council of Chief Information Officers (CCIO)
- All your base are belong to us



