10 May 2016
Economist Paul Krugman loves to coin phrases, and a favourite of mine is the “magic asterisk”, referring to a footnoted extra calculation that is both
- critical to the financial credibility of a piece of public policy, and
- completely made up.
The NRPP Business Case doesn’t really hide its magic asterisk, it puts it right in the executive summary.
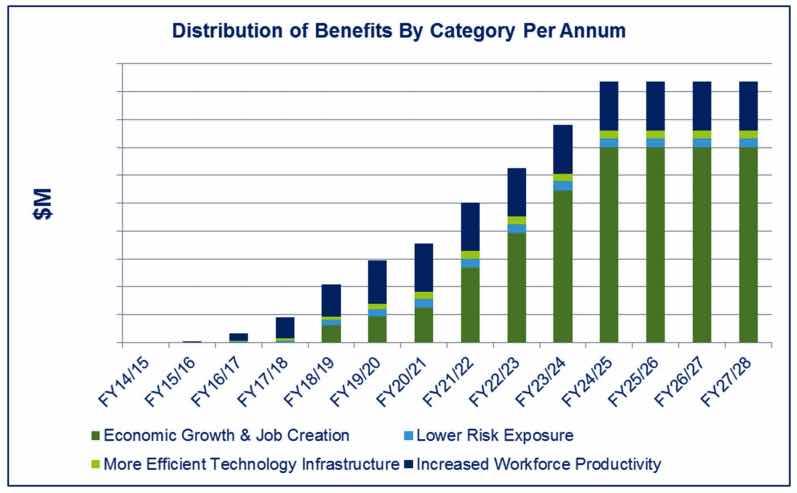
See it? That little stack of green bars? The NRPP business case would have you believe that the lion’s share of project benefit is going to come from “economic growth and job creation” as a result of this technology and business process realignment project.
Please stop laughing.
Please stop.
The leap of faith you must make is to think that not only will an improved system speed up the time between natural resource project conception and delivery (I can buy that) but also it will result in a permanent and persistent rise in the rate of resource extraction in the province (that one is harder). That’s where the green bars marching to the right come from.
So, pop quiz, what is more likely to result in a lasting rise in rates of resource extraction:
Like all good magic asterisks, the NRPP plan involves real mathematics, applied to nonsensical inputs. In this case net present value calculations applied to unrealistic projections about likely upcoming major project investments in BC:
- Calculation based on approval of 8 new mines and 3 LNG facilities after NRPP is implemented
- 12-month acceleration of decision timelines for major mines and LNG facilities will create a present value benefit from faster revenue realization
- Conservative estimate which excludes any impact on other revenue streams
- Data for calculations was sourced from the BC Jobs Plan and LNG Strategy
- Present value calculations assume a 4.5% discount rate and a 30-year timeframe
NRPP Business Case, Key Revenue Assumptions, Page 59
See it? In order to make millions through faster approvals of major projects, only two things have to happen:
- We need 8 new mines and 3 LNG projects to go through.
- The new process actually has to make them go through faster.
So, no problem.
Stop laughing.
Please stop it.
It will be on time, on budget. Guaranteed.
05 May 2016
A reader asked me whether the pursuit of a magic IT bullet in BC natural resource management is a result of ignorance, and I don’t really think so.
If anything, it’s a result of magical thinking, a “drunk looking for keys under the lamppost” reaction to the extremely difficult problem of integrating resource management operations.

As an example of how hard integration can be, consider the relatively “simple” problem of bringing management of resource roads under a single statute and operational regime. The process kicked off in 2008, with legislation introduced and then withdrawn as the government came to grips with the huge number of stakeholders they’d forgotten to engage. Eight years on, the process still hasn’t come to a conclusion.
Yet the good folks at NRPP are willing to promise the political masters they can integrate decision making across multiple resources and land values, through the application of nifty technology, new legislation and business process changes.
There is a going to be a promise/delivery gap here, it’s just a question of how much money will be spent before that becomes clear.
It’s worth noting that this promise has been made before.

The BC Liberal government arrived in 2001 with the grandiosely named “New Era” platform, which included a promise to:
Eliminate the backlog and delays in Crown land applications, which have cost over $1 billion and 20,000 lost jobs.
Fifteen years later, the NRPP Business Case makes basically the same promise, on the same premise – that removing backlogs and delays will result in a permanent increase in provicial resource revenues.
The status quo is unsustainable as the current constraints and challenges faced by the NRS will lead to greater delays in project approval timelines, increases in authorizations backlogs, lost economic opportunities, increases in legal and financial risk, and declining levels of satisfaction with NRS services provided to the public, First Nations, clients and proponents. Investing in NRPP is central to enabling government to deliver on many of the commitments made in the BC Jobs Plan and in the June 2013 Speech from the Throne…
NRPP Executive Summary, 2014
The folks charged with implementing the 2001 “New Era” promise came up with essentially the same solution that NRPP is peddling today:
The government of British Columbia, as outlined in the New Era for Business, Investment and Opportunity document, states its commitment to create a cost-competitive business climate and to boost private sector, investment in the resource sector including the booming Oil and Gas sector. In support of this commitment the Ministry of Sustainable Resource Management has initiated a Business Strategy and Transition Plan aimed at constructing a government-wide registry of land and resource encumbrances. This registry will significantly reduce the costs and shorten the time required in gaining access to land and resources for both government and businesses.
Business Strategy and Transition Plan, Integrated Registry Project, 2002/10/31
Sound familiar?
The only differences are of scope:
- The 2002 Integrated Registries Project only aimed to consolidate information and processes around land tenuring.
- NRPP aims to consolidate all land and resource decision making, on major projects as well as operational tenuring.
- The 2002 Integrated Registries Project was given a $14M budget.
- NRPP has been given a $57M budget just for Phase One.
Unlike NRPP, we already know how the 2002 Integrated Registries Project panned out:
- The various land tenuring acts, which were going to be combined into a single new piece of legislation feeding a single statutory register, were left intact.
- The register itself was downgraded from a single statutory point of truth, to a somewhat real-time data warehouse of land tenuring information.
- 15 years on, land management decisions are still considered “too slow”, to the extent that NRPP can assert that “as a result of NRPP, the time needed to approve major projects will be reduced, and government will achieve a significant benefit from realizing revenues sooner.”
It’s not that I don’t think NRPP will have some valuable results, just as the Integrated Registries Project did. I just think that, like the old registries project, those predictable benefits could be realized at about 10% of the cost if they were prioritized right up front, and the grandiose promises (predestined to failure) were left at the door.
05 May 2016
Far and away the most amusing part of the NRPP Business Case that the government quietly placed online this March is the “Financial Benefits & Lifecycle Costs” section, the part where they are supposed to make the dollars-and-cents case for the project.
In order to ensure transparency and instill public confidence in the project, all the dollar figures have been replaced with “$X” in the text. So awesome!
But just as good, in the Lower Risks Exposure section, they outline in clear prose some of the resource management disasters of the past 10 years:
- A dam collapsed and caused significant property damage after the NRS failed to enforce the need for repairs and maintenance. Contributing factors included a lack of effective record keeping, inaccurate risk/consequence ratings given to the dam, and a lack of action to address decades of warnings that the dam was in poor condition. Settlements paid by government to affected parties totaled more than $X M
- A District Manager approved a forest development plan and awarded multiple cut blocks in a watershed; however, the decision was inappropriate and not durable because the plan was contrary to regulations and it did not consider impacts to endangered animal populations. The case was settled for $X M
- An oil and gas company acquired a tenure in northeastern British Columbia only to find out that the NRS had not disclosed that the tenure was in an area that was considered historically and spiritually significant by a local aboriginal group. The matter proceeded through an extensive litigation process and settled for $X M
That’s some pretty bad stuff! Not the kind of thing that makes it into the average government press release!
But, being information technology people, they cannot help themselves, they look at this bad stuff and they think, “if only people had the right information at the right time, none of this would have happened”.

Through the implementation of an integrated spatial and operational database, a risk-based framework for compliance and enforcement activities across the province, and through facilitating information sharing across lines of business, NRPP will contribute to a significant reduction in legal risk and potentially a reduction in litigation and settlement costs.
Aren’t IT people cute! Don’t you just want to stroke their fur and take them home?!?
Non-IT people might have a different reaction to that list of calamities. They might think, “political pressures that make speed of permit approval the primary metric of good resource management are causing corners to be cut and very expensive/damaging mistakes to be made.”
Unfortunately, those are the kinds of thoughts that will quickly end careers if expressed out loud in government.
So instead, we have a new $57M IT megaproject. The kind of project that has the maximum likelihood of failure and delay: a multi-year, multi-million-dollar, maximum scope project.
Don’t worry though, it will be delivered “on time and on budget”.
04 May 2016
As Vaughn Palmer said last week,
“Another day, another bogus claim from the B.C. Liberals that a major capital project is on time and on budget.”
We in the IT consulting field are perhaps numb to the eternal cycle of cutting scope, pushing the delivery date, and declaring victory, but in the cut-throat world of politics, these things have consequences.
At the very least, you’ll be publicly mocked when you do it, as on Tuesday the NDP mocked the Liberals for repeated non-delivery of an online Civil Resolution Tribunal.

Mind you, most of these wounds are self-inflicted, as this government just will not let go of the core principles of enterprise IT failure:
- make the budget as large as possible;
- make the scope as broad as possible; and,
- hire international IT consultancies so large that they don’t care whether your project succeeds or not, just so long as they can bill out as much as possible.
These are the guiding principles that have brought them ICM, MyEdBC, Panorama, and enough other miscues that the Vancouver Sun felt compelled to run a whole series of articles on IT failure.
And there’s another one in progress!
The $57.2 million Natural Resource Permitting Project (NRPP) Phase One is now at least a year behind schedule, based on a business plan document that was quietly placed online this March.
This is the same NRPP business plan I requested via FOI in 2014, and was given 200 blank pages of PDF in reply. The plan released March 2016 still has all the dollar figures blanked out. That’s right, they released a “business plan” without the numbers!
According to the “Investment Roadmap” year one of the project, fiscal 2014/15 which ended 12 months ago, should have delivered the following results:
- New legislative framework in place
- High-priority business processes re-engineered
- Initial foundational integrated spatial-temporal operational database available
- IM/IT and priority finance operating model and processes re-engineered
- New Common Client architecture available
- Transformation governance model in place
Has any of this happened?
The project capital plan, written last fall, lists similar capabilities as items to be delivered in the future.
According to the business plan, on the basis of which $57M capital dollars were committed in 2014, the project is now at least a year behind.
As we can see from the discrepency between the older business plan and the capital plan, the usual process has begun: the goal posts are on the move. Next up, the bogus claims.
Fortunately, the international consultants are billing hard so we’ll be back on schedule shortly. In the end everything will be delivered “on time, and on budget”, I guarantee it.
29 Apr 2016
I’ve had a productive couple of weeks here, despite the intermittently lovely weather and the beginning of Little League baseball season (not coaching, just supporting my pitcher-in-training).

The focus of my energies has been a long-awaited (by me) update to the OGR FDW extension for PostgreSQL. By binding the multi-format OGR library into PostgreSQL, we get access to the many formats supported by OGR, all with just one piece of extension code.
As usual, the hardest part of the coding was remembering how things worked in the first place! But after getting my head back in the game the new code flowed out and now I can reveal the new improved OGR FDW!

The new features are:
- Column name mapping between OGR layers and PgSQL tables is now completely configurable. The extension will attempt to guess mapping automagically, using names and type consistency, but you can over-ride mappings using the table-level
column_name option.
-
Foreign tables are now updateable! That means, for OGR sources that support it, you can run INSERT, UPDATE and DELETE commands on your OGR FDW tables and the changes will be applied to the source.
- You can control which tables and foreign servers are updateable by setting the
UPDATEABLE option on the foreign server and foreign table definitions.
- PostgreSQL 9.6 is supported. It’s not released yet, but we can now build against it.
- Geometry type and spatial reference system are propogated from OGR. If your OGR source defines a geometry type and spatial reference identifier, the FDW tables in PostGIS will now reflect that, for easier integration with your local geometry data.
- GDAL2 and GDAL1 are supported. Use of GDAL2 syntax has been made the default in the code-base, with mappings back to GDAL1 for compatibility, so the code is now future-ready.
- Regression tests and continuous integration are in place, for improved code reliability. Thanks to help from Even Roualt, we are now using Travis-CI for integration testing, and I’ve enabled a growing number of integration tests.
As usual, I’m in debt to Regina Obe for her timely feedback and willingness to torture-test very fresh code.
For now, early adopters can get the code by cloning and building the project master branch, but I will be releasing a numbered version in a week or two when any obvious bugs have been shaken out.



