20 Aug 2010
If you find yourself writing a query like this:
... WHERE ST_Intersects(ST_Buffer(g1, r), g2)
Stop. Take a cleansing breath. Do this:
... WHERE ST_DWithin(g1, g2, r)
With the carbon emissions you save doing it the efficient way, you can afford to drive to the ice cream store for a well-deserved reward.
16 Aug 2010
 Did you know that OpenGeo is hiring a software engineer? It’s true. Let’s build something beautiful together.
Did you know that OpenGeo is hiring a software engineer? It’s true. Let’s build something beautiful together.
06 Aug 2010
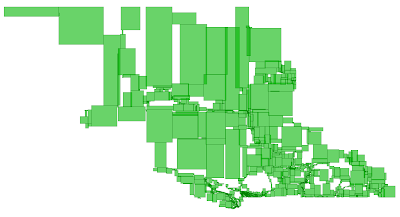 Noticing this a little late, but have a peak at these posts from Chris Hodgson about how the R-Tree fails for variable density GIS data, and his approach to a packing process. Unfortunately, packing is a post-facto process, and it’s not clear to me how we would do it with the GiST infrastructure that undergirds the PostGIS database. But it’s nice to see a good R-Tree and a reminder of just how ugly they can get under the covers.
Noticing this a little late, but have a peak at these posts from Chris Hodgson about how the R-Tree fails for variable density GIS data, and his approach to a packing process. Unfortunately, packing is a post-facto process, and it’s not clear to me how we would do it with the GiST infrastructure that undergirds the PostGIS database. But it’s nice to see a good R-Tree and a reminder of just how ugly they can get under the covers.
27 Jul 2010
 OK, this is the last time I’m going to remind you: FOSS4G 2010 is coming up fast. September 6-9 in Barcelona, Spain. The presentation call was massive (360 submissions for 120 slots) as was the workshop call. So register soon and make your hotel reservations while you can! That is all.
OK, this is the last time I’m going to remind you: FOSS4G 2010 is coming up fast. September 6-9 in Barcelona, Spain. The presentation call was massive (360 submissions for 120 slots) as was the workshop call. So register soon and make your hotel reservations while you can! That is all.
22 Jul 2010
I had cable guys in my house turning on basic cable, and they noticed that my cable modem was old. When I say “old”, I mean “I think I got it when we moved into the house almost 10 years ago”. So they said, “here, have a new one”. My maximum download speed quadrupled overnight. If you’ve got an old cable modem, figure an excuse to get a new one.



