22 Feb 2010
Third day, best day. There are four MapServer developers now working hard on implementing the rendering plugin changes. Thomas Bonfort is doing the core work, Steve Lime is re-working the old GD renderer, Dan Morissette is creating support for hatched styles, and Assefa is doing KML output.
In Geoserver land, Andrea Aime added support for variable substitution in SLD, which means that URL parameters can now be passed into SLD styling rules, to create dynamic styling effects. Tim Schaub and Justin Deoliveira also demonstrated an application that warms the cockles of my heart: using their new GeoScript extension they made a web-based application that takes in SQL and spits out maps. So now I can type PostGIS queries into a web page and see the results overlaid on a map. Crunchy!

Howard Butler has contributed some work on the auto-projection support in MapServer and is now working on LibLAS Oracle support. He also tracked down an excellent pastrami sandwich. So I am told.
In PostGIS world, Jeff Adams finished his lat/lon formatter and logged his first commit: an impressive complete collection of unit tests, documentation and a working function (ST_AsLatLonText) that can turn POINT(-120.5 12.25) into 12°15’0”N 120°30’0”W. Oliver continues to fix up the text output functions. And I completed my first cut of the WKT output. Curve support really adds a lot of overhead to these things! There are lots of variants and curves have more and sillier formatting rules than linear features. David Zwarg has continued beavering through tickets in the WKTRaster subsystem.
Thanks again to our sponsors, tonight we are heading out to dinner at a Malaysian restaurant in Chinatown.
21 Feb 2010
Today the Geoserver, MapServer and OpenLayers teams got together and really showed off the “making things work together better” theme. Starting from Andrea Aime’s new “WMS rotation” feature, Daniel Morissette implemented the same feature with the same semantics in MapServer, while Andreas Hocevar implemented client support for the feature into OpenLayers. During testing, a small bug showed up in the Geoserver implementation, which Andrea fixed.
The final result is shown in this screenshot: layers from Geoserver and MapServer viewed and rotated together within OpenLayers.
The MapServer team is now really digging into a couple major goals: reading projection information automatically from data sources; and, making the rendering subsystem pluggable. Here they are deep in discussion on the rendering design:

Automatic projection reading will make it easier for new users to work with data in mixed projections, because they will no longer have to manually populate PROJECTION blocks for their layers. They will be able to just set PROJECTION to AUTO.
The pluggable rendering upgrade is mostly of interest to programmers, but because it will clean up the plumbing in drawing maps, it will allow new features like KML, PDF and SVG output to be added much more easily. In fact, Assefa is currently working on KML output, using the new rendering design.
Keeping to himself quietly, Alan Boudreault is tying the XML Mapfile more tightly into MapServer. In the last revision, XML Mapfiles could be transformed to .map format with a utility. In the next revision, it will be possible to use them directly from the MapServer CGI program.
Over on the Geoserver side, Andrea Aime arrived from Italy last night, and today is adding the WMS GetStyles operation to Geoserver. Andreas Hocevar is working on tying together printing support in Geoserver and GeoExt. The scripting engine crew continues to beaver away on Javascript/Python/Scala scripting in Geoserver.
In PostGIS land, Olivier Courtin has blasted a pile of changes into PostGIS trunk, working on moving GML/KML/SVG support down into the core geometry library, where they will be easier to reuse. On a similar tack, I’ve been working on writing a new WKT emitter, that is easier to maintain and supports ISO WKT for extended types and dimensions.
Thanks again to our sponsors! In an hour we will be settling in to watch the Canada/USA hockey game on the big screen in the Open Plans penthouse. Go Canada!
Update: Canada disappoints! I blame Brodeur.
20 Feb 2010
On a bright day in NYC, we all convened in the sunny Open Plans event room for the first day. As in last years sprint, the morning was spent in planning and discussions, and the afternoon folks began digging in.
The MapServer team talked about release plans for 6.0, and came up with an ambitious release plan. They recognize that not every item on the plan will make the final cut, but hope that most will find either funded or community effort to bring about. Among the highlights (to me):
Pluggable renderer would allow a much cleaner rendering chain, and new renderers for new formats to be more easily added. filterObj to enhance the power of MapServer querying and support OGC Filter fully (and incidentally leverage the power of databases like PostGIS more fully). Named styles to allow re-use of style objects through a map file, instead of repeating the definitions over and over.
I also talked with Steve Lime and Jim Klassen about a bug in the one-pass rendering code that is making complex WFS queries fail. We think we have a solution and Assefa is doing the final tests.
The PostGIS discussions were about our 2.0 roadmap and what the implications of various changes are. Unfortunately, most of my proposed/desired changes are predicated are a large change to the underlying data serialization, so going forward requires a good deal of bravery – I have to burn down the village in order to save it. Olivier Courtin is working on more tractable new features: a polyhedral surface, suitable for storing 3D buildings and other objects that have grown increasingly common.
David Zwarg and Jeff Adams from Avencia joined the PostGIS group, and are working hard already: David on WKTRaster and Jeff on a geographic coordinates formatting routine. Don’t tell Jeff, but if he gets the output formatter working, I’m just going to ask him to try and write an ingester.
Justin Deoliveira and Tim Schaub began working on improving the scripting extensions to Geoserver, Tim working on the server-side JavaScript and Justin working on the Python (and David Winslow working on Scala!). Andreas Hocevar has begun a Google Maps V3 API layer for OpenLayers, which will allow Google layers without API keys in OpenLayers (yay!).
As usual, the team had to be driven into the night bodily at the end of the day – it is hard to pry nerds from their code.
Thanks to our 2010 sprint sponsors, for keeping us well supplied with food, drinks and coffee throughout this busy week!
Postscript: At the end of the day, Olivier and I settled on an order-of-operations to move towards the new database serialization in PostGIS. Step one, remove the current places in the code where the serialization pokes up into function code and get it completely isolated underneath a serialize/deserialize layer.
19 Feb 2010

Here we go! 23 programmers are winging their way to the Big Apple to take part in the New York code sprint, combining coding talent talent from MapServer, PostGIS, GDAL, OpenLayers, Geoserver, LibLAS, and, and, and!
I am in the air right now, and am looking forward to meeting up with the sprinters at the Broome Street Bar (363 W Broadway) this evening.
Thanks to our 2010 sprint sponsors, for keeping us well supplied with food, drinks and coffee throughout this busy week!
18 Feb 2010
I recently bought a set of wireless handsets that include a digital answering machine, so I figured I should be economical and cancel my voicemail. This is the internet age, so I pay my bills and manage my phone account online. Go to my account page, a little hunting, and there’s all the options available for voice mail.
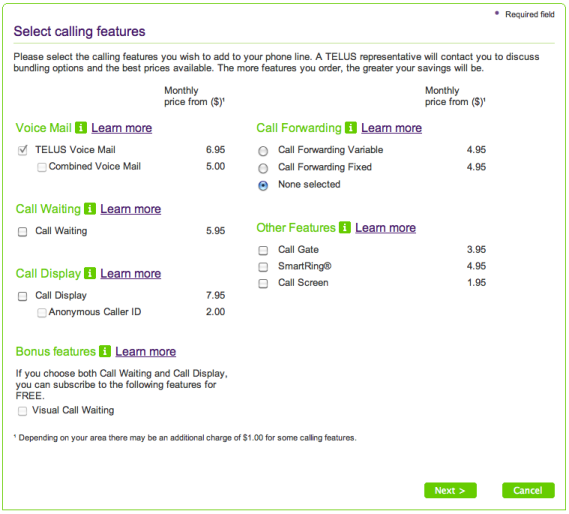
Note that the check mark next to voicemail service is grayed out! You can add services via the web interface, but you can’t remove them! I’d switch to the other phone company, but there isn’t one. All I’ve got is the cable company, and they recently shut off my internet for a week, which put somewhat of a crimp in my working-from-home (became working-from-cafe).



