



FOSS4G 2010 Savings
02 Jan 2010
 If you know you’re going to FOSS4G 2010 in Barcelona this year, you can save 20% by taking advantage of the Sooper Dooper Early Registration rates. Rates end January 15, the early bird gets the savings.
If you know you’re going to FOSS4G 2010 in Barcelona this year, you can save 20% by taking advantage of the Sooper Dooper Early Registration rates. Rates end January 15, the early bird gets the savings.
02 Jan 2010
If you know you’re going to FOSS4G 2010 in Barcelona this year, you can save 20% by taking advantage of the Sooper Dooper Early Registration rates. Rates end January 15, the early bird gets the savings.
22 Dec 2009
If “open” is good at making others loose, and less than free is the model for things outside your core revenue stream, why isn’t Microsoft giving away free advertising?
16 Dec 2009
Dan McKinley takes a look under the covers of a couple Python PostgreSQL abstraction layers:
Database client drivers intended for the same database can do drastically different things. By Python standards, the Postgres driver situation is completely schizo. There are a lot of them available - there are five dedicated Postgres drivers listed on the wiki, as opposed to just one for MySQL. People might choose different drivers for licensing reasons, for religious reasons, randomly (because they never did any analysis like I am about to do), or for completely inscrutable reasons because they are just plain out of their minds. You really would not believe how much blood I have seen spilled over Postgres client drivers.
16 Dec 2009
I typed “postgis” into Google this evening, and in addition to the exquisitely organized first entry there were two ads, one relevant (EnterpriseDB, the Postgres company) and one seemingly utterly random, for an English language school.
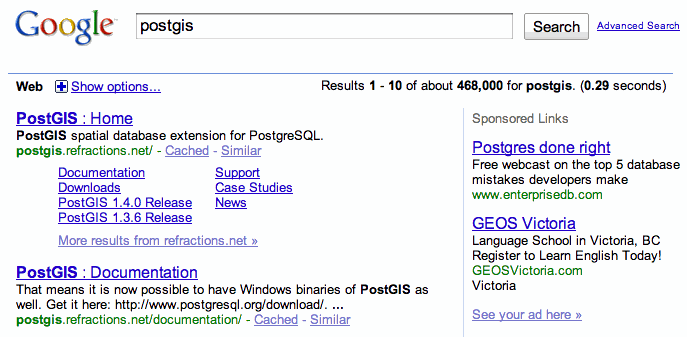
Has the Google algorithm made a mistake? How is this relevant? Well, the language school is in Victoria, BC, birth-place of PostGIS, but it gets better than that.
Here’s a picture of their sign, which I walked past every morning for almost five years, since the school shares a building (1207 Douglas Street) with Refractions Research, birth-company of PostGIS.

But wait, there’s more! The name of the school is “GEOS Language Academy”, and the GEOS spatial library was also created in Victoria, specifically to bring spatial predicate algorithms to PostGIS!
Poor Google algorithm, you never stood a chance.
15 Dec 2009
It’s not much, but it’s not nothing, my first ever patch to PostgreSQL proper is part of yesterday’s 8.4.2 release:
Fix incorrect logic for GiST index page splits, when the split depends on a non-first column of the index (Paul Ramsey)
It was just a minor syntax error I found because I was reading through that section of the code very, very, very closely (it’s true, I copy the work of smarter people than I) while implementing the indexes for GEOGRAPHY in PostGIS 1.5.