27 Jul 2009
 The 2009 FOSS4G presentations program has been selected! And I’m happy to report, it does include my talk, “The State of PostGIS”. Amazingly, I managed to restrict myself to only one submission this year, but I will be helping teach a PostGIS Workshop and giving a keynote address, “Beyond Nerds Bearing Gifts: The Future of the Open Source Economy”.
The 2009 FOSS4G presentations program has been selected! And I’m happy to report, it does include my talk, “The State of PostGIS”. Amazingly, I managed to restrict myself to only one submission this year, but I will be helping teach a PostGIS Workshop and giving a keynote address, “Beyond Nerds Bearing Gifts: The Future of the Open Source Economy”.
26 Jul 2009
 Tomorrow Steven Citron-Pousty and I will be teaching a workshop on building a geostack using open source components: PostGIS, GeoServer, OpenLayers, QGIS, GeoWebCache! After that, I will be around all week taking in the interesting geoparty that is GeoWeb. Last year was my first GeoWeb, and while I found the talks a bit dry (perhaps I am not ready for the brave new world of building modeling), I found the calibre of the attendees bracing – it was a great place to meet movers and shakers in the (corporate) geoworld. “Where 2.0 for grown-ups” indeed (for varying definitions of the term “grown-up”).
Tomorrow Steven Citron-Pousty and I will be teaching a workshop on building a geostack using open source components: PostGIS, GeoServer, OpenLayers, QGIS, GeoWebCache! After that, I will be around all week taking in the interesting geoparty that is GeoWeb. Last year was my first GeoWeb, and while I found the talks a bit dry (perhaps I am not ready for the brave new world of building modeling), I found the calibre of the attendees bracing – it was a great place to meet movers and shakers in the (corporate) geoworld. “Where 2.0 for grown-ups” indeed (for varying definitions of the term “grown-up”).
Update: The workshop is available online now, for your self-guided learning pleasure.
06 Jul 2009
For a while there, Microsoft made a lot of hay about the London Stock Exchange using Windows in their trading system.

As it turns out, too much hay. The LSE is now going to abandon their Windows trading system. As the author points out, IT failures aren’t all that rare, what is rare is learning about them. Usually the principals bury the body and move on to “Phase II”. In this case the principal was fired, and her replacement is hanging out the dirty laundry.
Another thing that is rare is for a dominant vendor to shoulder any blame for these kinds of failures. The usual principle is that, if everyone is doing it, it can’t possibly be stupid.
Did you buy an expensive web mapping server and then have to put it on a nightly re-boot cycle to avoid service degradation? Don’t worry, everyone is doing it, it doesn’t reflect badly on you.
Is all your e-mail locked in binary file archives, where a small corruption can render the entire archive irretrievable? Don’t worry, everyone is doing it, it doesn’t reflect badly on you.
It’s not an IT thing, really, it’s called “culture”, our common shared beliefs and idiosyncrasies.
 Did you start your day by repeatedly accelerating and decelerating a 4000lb metal box holding only yourself and a cup of coffee over a hot tar field, place your box in another hot tar field, and then hike over the tar field to a large glass box enter, and place yourself inside a further fabric covered box? Don’t worry, everyone is doing it, it doesn’t reflect badly on you.
Did you start your day by repeatedly accelerating and decelerating a 4000lb metal box holding only yourself and a cup of coffee over a hot tar field, place your box in another hot tar field, and then hike over the tar field to a large glass box enter, and place yourself inside a further fabric covered box? Don’t worry, everyone is doing it, it doesn’t reflect badly on you.
02 Jul 2009
“Green shoots…” ah, for the good old days of only two weeks ago, when green shoots were in our future…
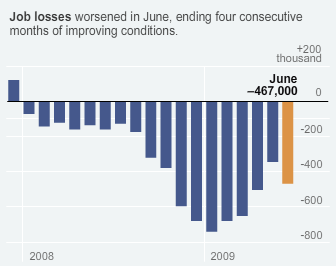
I never really understood why decreases in the rate of change of unemployment were considered such great news. “Good news, the second derivative has gone positive! we’re plunging into the abyss slightly less quickly!” Only in a world of rampant, congenital optimism – or statistics-induced myopia – could four months in which 18,300 Americans lost their jobs every day be described as a period of “improving conditions”.




