07 May 2009
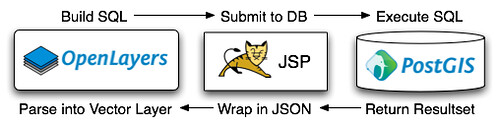
Update: I think the magnitude of the evil can only be appreciated if you see the JSP (yep, that’s all of it, that’s my “middleware”):
<%@ taglib uri="http://java.sun.com/jsp/jstl/sql" prefix="sql" %>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
<%@ page contentType="text/x-json" %>
<sql:query var="rs" dataSource="jdbc/postgisdb">
${param.sql}
</sql:query>
{"type":"FeatureCollection",
"features":[
<c:forEach var="row" items="${rs.rows}">
{"type":"Feature",
"geometry":<c:out value="${row.st_asgeojson}" escapeXml="false" />,
"properties":{
<c:forEach var="column" items="${row}">
<c:if test="${column.key != 'st_asgeojson'}">
"<c:out value="${column.key}" escapeXml="false" />":
"<c:out value="${column.value}" escapeXml="false" />",
</c:if>
</c:forEach>
}},
</c:forEach>
]}
Update 2: Yes, I am being a bit sarcastic. Being able to compress the layer between the Javascript and the database into something this narrow is diabolical, and only possible because there is so much smarts in OpenLayers. I, for one, welcome our new hipster Javascript overlords.
Update 3: The “evil” is passing SQL unmediated from your browser directly into your database. It’s fun in a workshop (which is what I wrote this abomination for) but it’s not to be let out of the lab, lest global pandemic ensue.
30 Apr 2009
 OSGeo (your Open Source Geospatial Foundation) will be on the exhibition floor at Where 2.0 this year. I volunteered to be the “event manager” for OSGeo at Where 2.0 this year, but all the heavy lifting was done by Alex Mandel preparing for the American Geographical Society conference earlier this year. So thanks to Alex’s hard work, we’ll have some posters and brochures and handouts for the exhibit hall.
OSGeo (your Open Source Geospatial Foundation) will be on the exhibition floor at Where 2.0 this year. I volunteered to be the “event manager” for OSGeo at Where 2.0 this year, but all the heavy lifting was done by Alex Mandel preparing for the American Geographical Society conference earlier this year. So thanks to Alex’s hard work, we’ll have some posters and brochures and handouts for the exhibit hall.
Most importantly, we’ll have ourselves. Not booth bunnies, per se, but we have beautiful minds. Arnulf Christl, the OSGeo President, is coming in from Germany to attend, so there will be lots of good conversation to be had. Come ask us any question about open source, and we’ll be sure to give you an answer!
I’m also giving a workshop on spatial databases and web mapping. In fact, I’m preparing the material right now. Oh, how I hate preparing material – the being done is so much better than the doing.
29 Apr 2009

The best conference of the year just got better! They’ve chosen me as a keynote speaker! (My turnoffs include soggy popcorn, rainy days and false modesty.) See you in Sydney, mates! Throw another shrimp on the barbie! That’s not a keynote address, this is a keynote address.
Postscript: I just realized I learned everything I know about Australia before 1985.
28 Apr 2009
What have I been doing for the past month? Not much PostGIS, as the growing list of 1.4 milestone issues attests. Mostly residing in the fifth circle of marketing – web content.
28 Apr 2009
Recently, the OpenStreetMap project put out a very successful call for donations to upgrade their physical database infrastructure, from a dual-core Athlon with 8Gb of RAM and lots (~1Tb) of disk, to a quad-core Xeon with 32Gb of RAM and heaps (4Tb) of (15K RPM) disk.
 The speedy success of the hardware appeal (target reached in less than three days) was pretty impressive, but what really perked my (PostgreSQL fanboi) ears up was the news that the new hardware was going to run PostgreSQL, instead of the MySQL database OSM has used from the start. As of April 19, OSM is running their new API live on PostgreSQL.
The speedy success of the hardware appeal (target reached in less than three days) was pretty impressive, but what really perked my (PostgreSQL fanboi) ears up was the news that the new hardware was going to run PostgreSQL, instead of the MySQL database OSM has used from the start. As of April 19, OSM is running their new API live on PostgreSQL.
So, why has OSM abandoned the worlds most popular open source database? I asked the OSM folks, and this is what Tom Hughes of OSM told me:
Personally I’ve been very frustrated with MySQL from when I first got involved with running things. Some of the problem was of our own making in that we had a mix of MyISAM and InnoDB tables (originally everything was in MyISAM) and some tables were using MyISAM features that meant they couldn’t be easily moved to InnoDB.
On top of that it seemed that virtually any non-trivial query would completely defeat MySQL’s optimiser.
The comment about a mix of tables really hits home, since so many MySQL features are split across table types. Want transactions? InnoDB! Want full text search? MyISAM! Want spatial? MyISAM! Want spatial or full-text and transactions? Tough. The devil is in the details. When asked: does MySQL support spatial, transactions, full-text? the MySQL answer is “yes”, “yes”, “yes”, but the reality in production is not nearly so clear-cut.
Note that OSM is not using PostGIS for the main database at this time (their current data model of nodes and ways wouldn’t get much leverage from it) but it is used for other processes like OSM tile generation. And a growing number of people on the PostGIS users list seem to be using osm2pgsql to extract data from the OSM production server for rendering / analysis in PostGIS.
So, welcome OSM, to the PostgreSQL community!



