23 Jan 2009
Originally posted at GeoSpeil.
I have had a very geeky week, working on bringing the “cascaded union” functionality to PostGIS.
By way of background, about a year ago, a PostGIS user brought a question up. He had about 30K polygons he was unioning and the process was taking hours. ArcMap could to it in 20 minutes, what was up? First of all, he had an unbelievably degenerate data set, which really did a great job of exposing the inefficiency of the PostGIS union aggregate. Second, the union aggregate really was inefficient.
This is what his data looked like, before and after union.


The old PostGIS ST_Union() aggregate just naively built the final result from the input table: union rows 1 and 2 together, then add row 3, then row 4, etc. As a result, each new row generally made the interim polygon more complex — more vertices, more parts. In contrast, the “cascaded union” approach first structures the data set into an STR-Tree, then unions the tree from the bottom up. As a result, adjacent bits are merged together progressively, so each stage of the union does the minimum amount of work, and creates an interim result simpler than the input components.
Implementing this new functionality in PostGIS required a few steps: first, the algorithm had to be ported from JTS in Java to the GEOS C++ computational geometry library; second, the C++ algorithm in GEOS had to be exposed in the public GEOS C API; third, PostGIS functions to call the new GEOS function had to be added.
The difference on the test data set from our user was stark. My first cut brought the execution time in PostGIS from 3.5 hours to 4.5 minutes for the sample data set. That was excellent! But, we knew that the JTS implementation could carry out the same union on the same data in a matter of seconds. Where was the extra 4 minutes going in PostGIS? Some profiling turned up the answer.
Before you can run the cascaded union process, you need to aggregate all the data in memory, so that a tree can be built on it. The PostGIS aggregation was being done using ST_Accum() to build an array of geometry[], then handing that to the union operation. But the ST_Accum() aggregation was incredibly inefficient! Four minutes of overhead isn’t a bit deal when your union is taking hours, but now that it was taking seconds, the overhead was swamping the processing.
Running a profiler found the problem immediately. The ST_Accum() aggregate built the geometry[] array in memory, repeatedly memcpy()‘ing each interim array. So the array was being copied thousands of times. Fortunately, the upcoming version of PostgreSQL (8.4) had a new array_agg() function, which used a much more efficient approach to array building. I took that code and ported it into PostGIS, for use in all versions of PostgreSQL. That reduced the aggregation overhead to a few seconds.
Final result, the sample union now takes 26 seconds! A big improvement on the original 3.5 hour time.
Here’s a less contrived result, the 3141 counties in the United States. Using the old ST_Union(), the union takes 42 seconds. Using the new ST_Union() (coming in PostGIS 1.4.0) the union takes 3.7 seconds.


12 Jan 2009
As I mentioned earlier there is going to be a code sprint in Toronto from March 7-10, with a particular focus on C/C++ based open source geospatial software. The attendance list is now a veritable who’s who of Mapserver, PostGIS, GEOS, proj4 and GDAL developers. Of particular excitement to me, two members of the PostGIS team who I have not met – Mark Cave-Ayland and Regina Obe – are planning to attend.
Thanks to our event sponsors: Rich Greenwood, OSGIS.nl, Coordinate Solutions, LizardTech, and SJ Geophysics. If you or your organization would like to be an event sponsor too, please contact me directly!
07 Jan 2009
One of the first development projects I’m doing with OpenGeo is putting together a GUI for data loading/dumping in PostGIS. The command-line tools have served the project well for a long time, but with such good GUI tools like PgAdmin available for all the other interaction with the database, it is a shame to have to head to the command-line to load a shape-file.
[
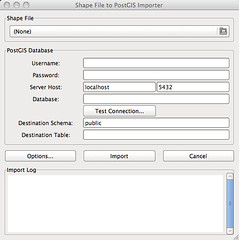
](http://www.flickr.com/photos/92995391@N00/3176884653/" title="PostGIS Loader GUI by pwramsey3, on Flickr)
Shape File Loader GUII’ve had a grand time learning GTK+ to build the GUI window, got it all laid out, and then spent some time re-working the output portions of the existing loader code so I could write into a database handle rather than to STDOUT.
I got everything hooked up, ran small small test cases (victory!) then got a big file, and hit the “Import” button and … everything froze for 20 seconds, then whoooosh all the logging information updated. What gives? Oh, right, I took control away from the GUI thread for 20 seconds while I was loading the data, then handed it back.
Mono uses GTK for their Linux widgets, and they have some good advice on how to build responsive applications – applications that stay usable and informative, even while doing computationally demanding tasks.
I thought I already knew the answer – I was going to have to put my loading process into its own thread and figure out all the joys of thread programming. I still may do that, but in the meantime I’ve implemented one of the other options the Mono project suggested. There is an “idle” event in GTK, which is thrown whenever the application has “time on its hands”. By breaking a large process into small chunks, and executing them during idle moments, the application remains responsive, and the work still gets done.
Is the application now “responsive”? I would argue, not really, it just seems responsive. But in this modern world, the appearance of a thing is usually just as good as the thing itself.
The code now looks a bit uglier though… instead of simply running the translation, the GUI moves through little stages: create the tables, load the first 100 features, the second, etc, finish the process. However, it’s now possible to stop an import mid-stream, and the logging information hits the window in real time.
05 Jan 2009
I have to blog this so the links are somewhere I can find them again! From Anselm Hook on Geowankers, links to the National Film Board of Canada 1968 short on GIS, “Data For Decision “, parts [1], [2] and [3].
Beep, beep, boop, boop, boop!
23 Dec 2008
Starting in the new year, I am going to be working full-time (well, slightly less due to child care needs) for OpenGeo, as the staff PostGIS expert. OpenGeo is best known as the home of GeoServer, but in the past year they’ve also built up a skilled team of OpenLayers user interface experts. So, architecturally, they’ve got a user interface layer, an application server layer, but what about database? To provide support for open source geo-applications, from database to interface, they want a database expert, and that’s where I come in.
I will still be available for PostGIS and Mapserver development projects, but the contracting agency will be OpenGeo now, instead of Clever Elephant. And in my gaps, I’ll be splitting my time between doing PostGIS development and marketing support for OpenGeo. (What’s “marketing support” mean? Material development, speaking, and blogging.)
I’m looking forward to having a bit more focus time for PostGIS, and also helping OpenGeo hone their vision of a pure open source geospatial company. As a “social enterprise”, OpenGeo has some financial flexibility in pursuing the audacious goal of a pure-play open source geo company, and some interesting productization opportunities that will be fun to work on.
Clarification (?): OpenGeo is a subproject of The Open Planning Project, which is in turn a part of the Lime Group, which is an umbrella for the many entrepreneurial pursuits of Mark Gorton (LimeWire is one of other members of the group). This Bloomberg article gives a good overview.



