15 Nov 2008
From James Fee:
[Open Street Map] comes off very “hacker” to many of my clients and they can’t get beyond that. I hope it doesn’t fall into what OSGeo is becoming.
Glurp?
Update: Clarification from James:
Why does OSGeo seem more concerned with creating new logos than creating case studies? To me that sums up its existence. Almost three years into OSGeo, what has it really done besides confederate some open source projects? Does this really help me sell open source projects? Email threads, are you kidding me?
http://wiki.osgeo.org/wiki/Case_Studies
If people put half the effort they do into logos and open source job lists that they do into case studies, maybe companies would look more at their products. I know Paul that you aren’t the president or director or whatever the head of OSGeo is, but this logo nonsense has got to stop and OSGeo has to embrace the real world.
Update 2: Almost as if to answer James (or at least to demonstrate that there are many, many minds about what OSGeo should “become”), Howard Butler posts to the OSGeo board list:
Marketing doesn’t write software, it doesn’t improve documentation, and it doesn’t streamline project communication…. I guess I’ve always had a bit of a problem with the marketing aspect of OSGeo, especially when its not at all clear to me who we’re marketing to other than the general GIS ether and for what purpose. IMO, the people using Open Source software are the ones who market it, not the people who make the software. [italics added] Could the OSGeo marketing proponents please set me straight on how I see this all wrong?
13 Nov 2008
Normally, minor releases just sail by… the bugs fixed are tiny things that don’t apply to your neck of the woods, but for 8.3.5 you will find this entry in the release notes:
Fix GiST index corruption due to marking the wrong index entry "dead" after a deletion (Teodor) This would result in index searches failing to find rows they should have found.
The PostGIS spatial index is built on top of GiST, so for any production table where entries are being deleted or updated, this bug could actually cause errors to crop up. Data would not be lost, but it would occasionally not be found in index-enabled searches.
If you are using PostGIS on PostgreSQL 8.3, upgrade to 8.3.5 as soon as possible. This bug has been seen in the wild, one of my clients just ran into it, it could affect you too.
Update: From Mark Cave-Ayland, the bug was only introduced during the last set of point releases, and was backpatched all the way to 8.1. So the complete list of affected PostgreSQL releases is: 8.1.14, 8.2.10 and 8.3.4. If your version is not one of those, you’re safe.
12 Nov 2008
One of the stranger rituals you will come across in Victoria is the annual fish stencil that the staff at the Goldstream Provincial Park put on for the kids every year during the salmon run. This is no ordinary fish stencil, because at Goldstream they use real dead salmon as the template.

Picture from Aaron Racicot on his recent Victoria trip.
Paint your fish, press a sheet of paper onto it, and voila, instant fish keepsake. If you come to Victoria in the late-October to early-November period, make sure Goldstream (just 20 minutes outside town) is on your agenda.
11 Nov 2008
While the “Obama-dot” in Charlie Savage’s rally snapshot is nice:

What really makes the picture, to my mind, is the snipers on the roof:

Nothing says democracy quite like snipers! :)
05 Nov 2008
I’ve always been a bit of a connoisseur of election maps, but most maps don’t really tell me much that I don’t already know. The maps I like best are those that show smaller geographies than usually reported (in Canada, maps of polls instead of ridings, in the USA, maps of counties instead of states) and those that show changes from previous results – “delta maps”. The New York Times is currently running one on their front page, here’s a snapshot.
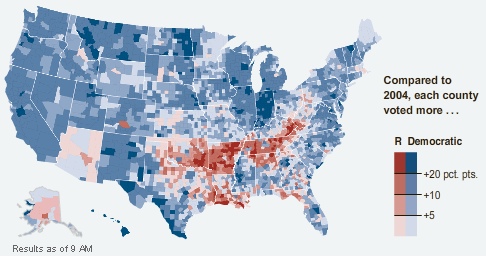
The colors are not reflective of number of votes, but of direction of movement. Hence, Montana colored blue even though McCain won it, because in every county Obama did better than Kerry did in 2004.
One of the things I found curious about the numbers in the paper today is that while Obama won a strong Electoral College victory, his popular vote share is not much different from the share Bush won in 2004, and Bush won a squeaker in the Electoral College. The map tells the tale.
McCain didn’t lose support across the board, he actually improved on Bush in places, but mostly in places where the Republicans were already winning smashing majorities – more votes in Alabama don’t get you any closer to the Presidency. So a respectable showing in the popular vote translates into an Electoral College whomping.
Somewhat disturbing is how nicely the red areas map into the phrase “rural white voters in former slave states”. History just never goes away, does it?



