



Waiting for PostGIS 3: Parallelism in PostGIS
25 Aug 2019Parallel query has been a part of PostgreSQL since 2016 with the release of version 9.6 and in theory PostGIS should have been benefiting from parallelism ever since.
In practice, the complex nature of PostGIS has meant that very few queries would parallelize under normal operating configurations – they could only be forced to parallelize using oddball configurations.
With PostgreSQL 12 and PostGIS 3, parallel query plans will be generated and executed far more often, because of changes to both pieces of software:
- PostgreSQL 12 includes a new API that allows extensions to modify query plans and add index clauses. This has allowed PostGIS to remove a large number of inlined SQL functions that were previously acting as optimization barriers to the planner.
- PostGIS 3 has taken advantage of the removal of the SQL inlines to re-cost all the spatial functions with much higher costs. The combination of function inlining and high costs used to cause the planner to make poor decisions, but with the updates in PostgreSQL that can now be avoided.
Increasing the costs of PostGIS functions has allowed us to encourage the PostgreSQL planner to be more aggressive in choosing parallel plans.
PostGIS spatial functions are far more computationally expensive than most PostgreSQL functions. An area computation involves lots of math involving every point in a polygon. An intersection or reprojection or buffer can involve even more. Because of this, many PostGIS queries are bottlenecked on CPU, not on I/O, and are in an excellent position to take advantage of parallel execution.
One of the functions that benefits from parallelism is the popular ST_AsMVT() aggregate function. When there are enough input rows, the aggregate will fan out and parallelize, which is great since ST_AsMVT() calls usually wrap a call to the expensive geometry processing function, ST_AsMVTGeom().
Using the Natural Earth Admin 1 layer of states and provinces as an input, I ran a small performance test, building a vector tile for zoom level one.
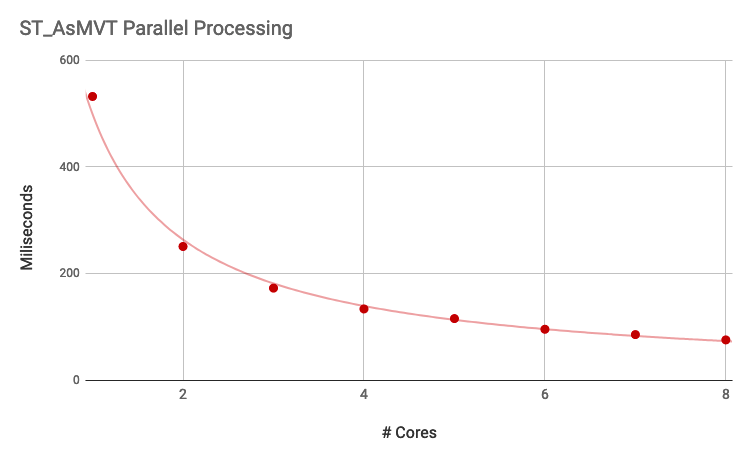
Spatial query performance appears to scale about the same as non-spatial as the number of cores increases, taking 30-50% less time with each doubling of processors, so not quite linearly.
Join, aggregates and scans all benefit from parallel planning, though since the gains are sublinear there’s a limit to how much performance you can extract from an operation by throwing more processors at at. Also, operations that do a large amount of computation within a single function call, like ST_ClusterKMeans, do not automatically parallelize: the system can only parallelize the calling of functions multiple times, not the internal workings of single functions.