



ST_Subdivide all the Things
13 Nov 2019This post originally appeared in the CARTO blog.
One of the things that makes managing geospatial data challenging is the huge variety of scales that geospatial data covers: areas as large as a continent or as small as a man-hole cover.
The data in the database also covers a wide range, from single points, to polygons described with thousands of vertices. And size matters! A large object takes more time to retrieve from storage, and more time to run calculations on.
The Natural Earth countries file is a good example of that variation. Load the data into PostGIS and inspect the object sizes using SQL:
SELECT admin, ST_NPoints(the_geom), ST_MemSize(the_geom)
FROM ne_10m_admin_0_countries
ORDER BY ST_NPoints;
- Coral Sea Islands are represented with a 4 point polygon, only 112 bytes.
- Canada is represented with a 68159 point multi-polygon, 1 megabytes in size!
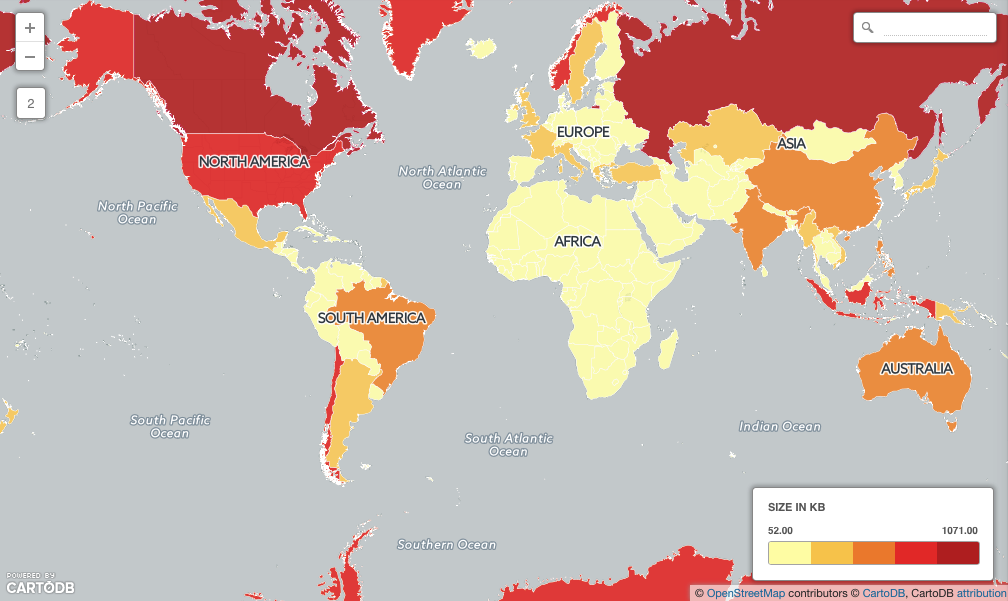
Over half (149) of the countries in the table are larger than the database page size (8Kb) which means they will take extra time to retrieve.
SELECT Count(*)
FROM ne_10m_admin_0_countries
WHERE ST_MemSize(the_geom) > 8192;
We can see the overhead involved in working with large data by forcing a large retrieval and computation.
Load the Natural Earth populated places into PostGIS as well, and then run a full spatial join between the two tables:
SELECT Count(*)
FROM ne_10m_admin_0_countries countries
JOIN ne_10m_populated_places_simple places
ON ST_Contains(countries.the_geom, places.the_geom)
Even though the places table (7322) and countries table (255) are quite small the computation still takes several seconds (about 30 seconds on my computer).
The large objects cause a number of inefficiencies:
- Geographically large areas (like Canada or Russia) have large bounding boxes, so the indexes don’t work as efficiently in winnowing out points that don’t fall within the countries.
- Physically large objects have large vertex lists, which take a long time to pass through the containment calculation. This combines with the poor winnowing to make a bad situation worse.
How can we speed things up? Make the large objects smaller using ST_Subdivide()!
First, generate a new, sub-divided countries table:
CREATE TABLE ne_10m_admin_0_countries_subdivided AS
SELECT ST_SubDivide(the_geom) AS the_geom, admin
FROM ne_10m_admin_0_countries;
Now we have the same data, but no object is more than 255 vertices (about 4Kb) in size!
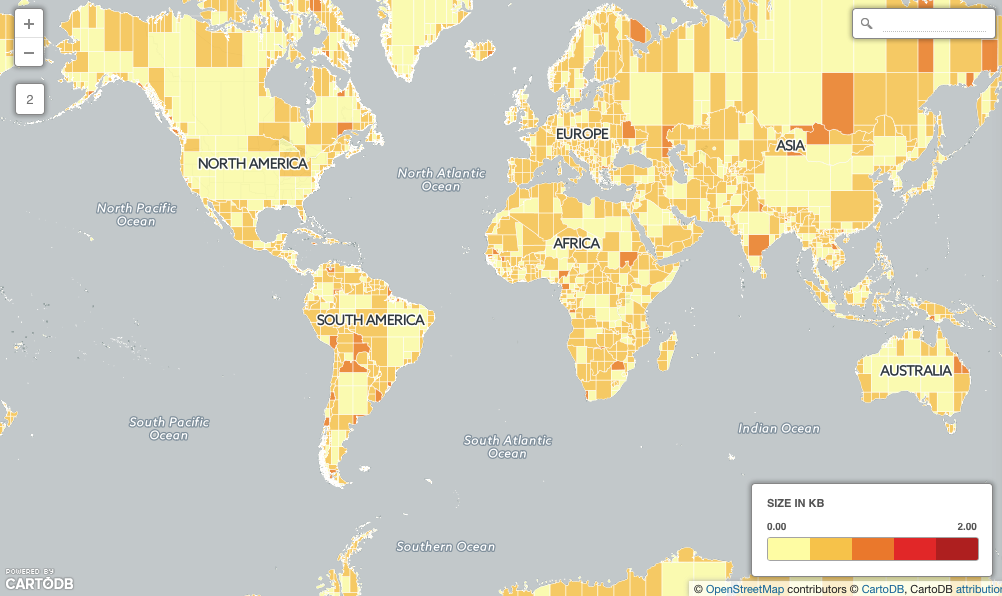
Run the spatial join torture test again, and see the change!
SELECT Count(*)
FROM ne_10m_admin_0_countries_subdivided countries
JOIN ne_10m_populated_places_simple places
ON ST_Contains(countries.the_geom, places.the_geom)
On my computer, the return time about 0.5 seconds, or 60 times faster, even though the countries table is now 8633 rows. The subdivision has accomplished two things:
- Each polygon now covers a smaller area, so index searches are less likely to pull up points that are not within the polygon.
- Each polygon is now below the page size, so retrieval from disk will be much faster.
Subdividing big things can make map drawing faster too, but beware: once your polygons are subdivided you’ll have turn off the polygon outlines to avoid showing the funny square boundaries in your rendered map.
Happy mapping and querying!