



Waiting for Postgis 3.1: Vector tile improvements
19 Nov 2020This is a guest post from Raúl Marín, a core PostGIS contributor and a former colleague of mine at Carto. Raúl is an amazing systems engineer and has been cruising through the PostGIS code base making things faster and more efficient. You can find the original of this post at his new personal tech blog. – Paul
I’m not big on creating new things, I would rather work on improving something that’s already in use and has proven its usefulness. So whenever I’m thinking about what I should do next I tend to look for projects or features that are widely used, where the balance between development and runtime costs favors a more in depth approach.
Upon reviewing the changes of the upcoming PostGIS 3.1 release, it shouldn’t come as a surprise then that most of my contributions are focused on performance. When in doubt, just make it faster.
Since CARTO, the company that pays for my lunch, uses PostGIS’ Vector Tile functions as its backend for dynamic vector maps, any improvement there will have a clear impact on the platform. This is why since the appearance of the MVT functions in PostGIS 2.4 they’ve been enhanced in each major release, and 3.1 wasn’t going to be any different.
In this occasion the main reason behind the changes wasn’t the usual me looking for trouble, but the other way around. As ST_AsMVT makes it really easy to extract information from the database and into the browser, a common pitfall is to use SELECT * to extract all available columns which might move a lot of data unnecessarily and generate extremely big tiles. The easy solution to this problem is to only select the properties needed for the visualization but it’s hard to apply it retroactively once the application is in production and already depending on the inefficient design.
So there I was, looking into why the OOM killer was stopping databases, and discovering queries using a massive amount of resources to generate tiles 50-100 times bigger than they should (the recommendation is smaller than 500 KB). And in this case, the bad design of extracting all columns from the dataset was worsened by the fact that is was being applied to a large dataset; this triggered PostgreSQL parallelism requiring extra resources to generate chunks in parallel and later merge them together. In PostGIS 3.1 I introduced several changes to improve the performance of these 2 steps: the parallel processing and the merge of intermediate results.
The changes
Without getting into too much detail, the main benefit comes from changing the vector tile .proto such that a feature can only hold one value at a time. This is what the specification says, but not what the .proto enforces, therefore the internal library was allocating memory that it never used.
There are other additional changes, such as improving how values are merged between parallel workers, so feel free to have a look at the final commit itself if you want more details.
Performance comparison
The best way to see the impact of these changes is through some examples. In both cases I am generating the same tile, in the same exact server and with the same dependencies; the only change was to replace the PostGIS library, which in 3.0 to 3.1 doesn’t require an upgrade.
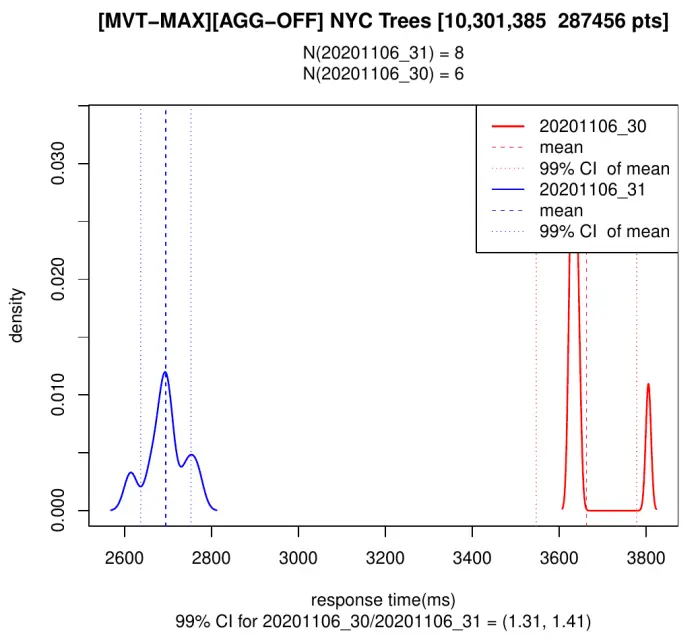
In the first example the tile contains all the columns of the 287k points in it. As I’ve mentioned before, it is discouraged to do this, but it is the simplest query to generate.
And for the second example, I’m generating the same tile but now only including the minimal columns for the visualization:
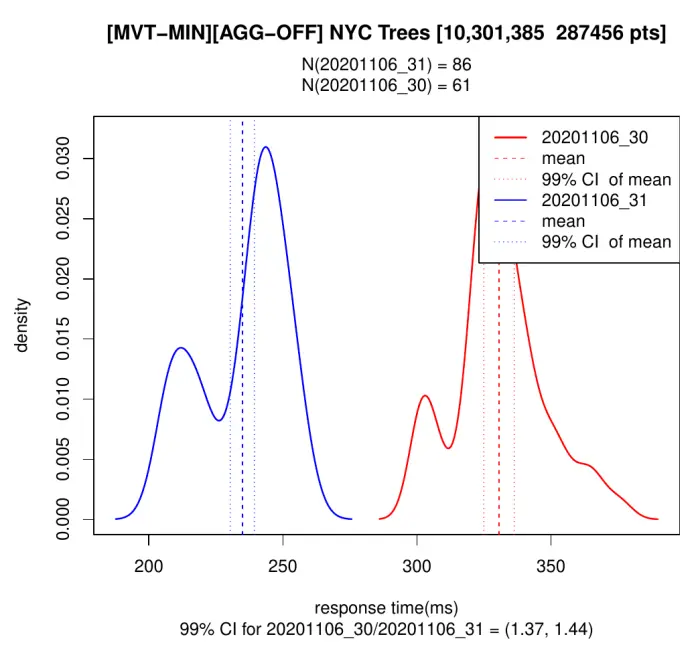
We can see, both in 3.0 and 3.1, that adding only the necessary properties makes things 10 times as fast as with the full data, and also that Postgis 3.1 is 30-40% faster in both situations.
Memory usage
Aside from speed, this change also greatly reduces the amount of memory used to generate a tile.
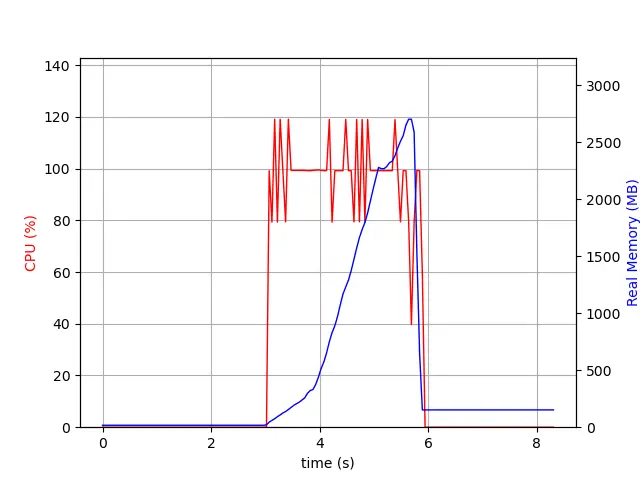
To see it in action, we monitor the PostgreSQL process while it’s generating the tile with all the properties. In 3.0, we observe in the blue line that the memory usage increases with time until it reaches around 2.7 GB at the end of the transaction.
We now monitor the same request on a server using Postgis 3.1. In this case the server uses around a third of the memory as in 3.0 (1GB vs 2.7GB) and, instead of having a linear increase, the memory is returned back to the system as soon as possible.
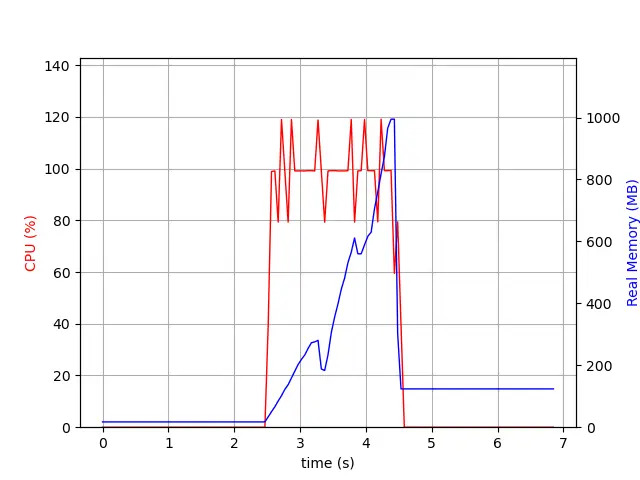
To sum it all up: PostGIS 3.1 is faster and uses less memory when generating large vector tiles.