



Waiting for PostGIS 3.1: Performance
16 Dec 2020This post originally appeared on the Crunchy Data blog.
Open source developers sometimes have a hard time figuring out what feature to focus on, in order to generate the maximum value for end users. As a result, they will often default to performance.
Performance is the one feature that every user approves of. The software will keep on doing all the same cool stuff, only faster.
For PostGIS 3.1, there have been a number of performance improvements that, taken together, might add up to a substantial performance gain for your workloads.
Large Geometry Caching
Spatial joins have been slowed down by the overhead of large geometry access for a very long time.
SELECT A.*, B.*
FROM A
JOIN B
ON ST_Intersects(A.geom, B.geom)
PostgreSQL will plan and execute spatial joins like this using a “nested loop join”, which means iterating through one side of the join, and testing the join condition. This results in executions that look like:
- ST_Intersects(A.geom(1), B.geom(1))
- ST_Intersects(A.geom(1), B.geom(2))
- ST_Intersects(A.geom(1), B.geom(3))
So one side of the test repeats over and over.
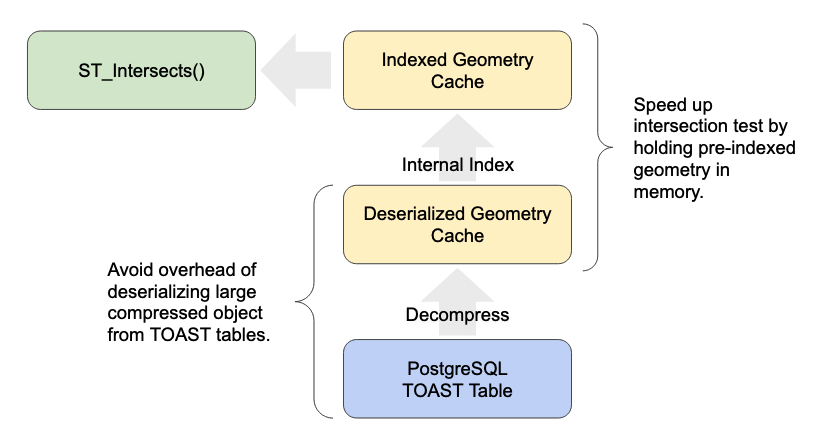
Caching that side and avoiding re-reading the large object for each iteration of the loop makes a huge difference to performance. We have seen 20 times speed-ups in common spatial join workloads (see below).
The fixes are quite technical, but if you are interested we have a detailed write-up available.
Header-only Geometry Reads
The on-disk format for geometry includes a short header that includes information about the geometry bounds, the spatial reference system and dimensionality. That means it’s possible for some functions to return an answer after only reading a few bytes of the header, rather than the whole object.
However, not every function that could do a fast read, did do a fast read. That is now fixed.
Faster Text Generation
It’s pretty common for web applications and others to generate text formats inside the database, and the code for doing so was not optimized. Generating “well-known text” (WKT), GeoJSON, and KML output all now use a faster path and avoid unnecessary copying.
PostGIS also now uses the same number-to-text code as PostgreSQL, which has been shown to be faster, and also allows us to expose a little more control over precision to end users.
How Much Faster?
For the specific use case of spatially joining, here is my favourite test case:
Load the data into both versions.
shp2pgsql -D -s 4326 -I ne_10m_admin_0_countries admin | psql postgis30
shp2pgsql -D -s 4326 -I ne_10m_populated_places places | psql postgis30
Run a spatial join that finds the sum of populated places in each country.
EXPLAIN ANALYZE
SELECT Sum(p.pop_max) as pop_max, a.name
FROM admin a
JOIN places p
ON ST_Intersects(a.geom, p.geom)
GROUP BY a.name
Average time over 5 runs:
- PostGIS 3.0 = 23.4s
- PostGIS 3.1 = 0.9s
This test is somewhat of a “worst case”, in that there are lots of very large countries in the admin data, but it gives an idea of the kind of speed-ups that are available for spatial joins against collections that include larger (250+ coordinates) geometries.