



Parallel PostGIS and PgSQL 11
10 Sep 2018A little under a year ago, with the release of PostgreSQL 10, I evaluated the parallel query infrastructure and how well PostGIS worked with it.
The results were less than stellar for my example data, which was small-but-not-too-small: under default settings of PostgreSQL and PostGIS, parallel behaviour did not occur.
However, unlike in previous years, as of PostgreSQL 10, it was possible to get parallel plans by making changes to PostGIS settings only. This was a big improvement from PostgreSQL 9.6, which substantial changes to the PostgreSQL default settings were needed to force parallel plans.
PostgreSQL 11 promises more improvements to parallel query:
- Parallelized hash joins
- Parallelized CREATE INDEX for B-tree indexes
- Parallelized CREATE TABLE .. AS, CREATE MATERIALIZED VIEW, and certain queries using UNION
With the exception of CREATE TABLE ... AS none of these are going to affect spatial parallel query. However, there have also been some none-headline changes that have improved parallel planning and thus spatial queries.
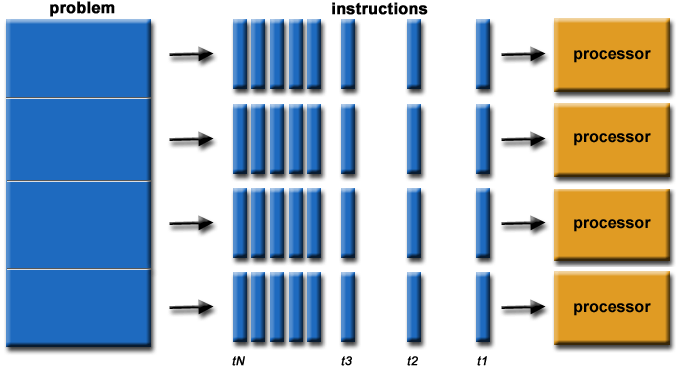
TL;DR:
PostgreSQL 11 has slightly improved parallel spatial query:
- Costly spatial functions on the query target list (aka, the
SELECT ...line) will now trigger a parallel plan. - Under default PostGIS costings, parallel plans do not kick in as soon as they should.
- Parallel aggregates parallelize readily under default settings.
- Parallel spatial joins require higher costings on functions than they probably should, but will kick in if the costings are high enough.
Setup
In order to run these tests yourself, you will need:
- PostgreSQL 11
- PostGIS 2.5
You’ll also need a multi-core computer to see actual performance changes. I used a 4-core desktop for my tests, so I could expect 4x improvements at best.
The setup instructions show where to download the Canadian polling division data used for the testing:
pda table of ~70K polygonsptsa table of ~70K pointspts_10a table of ~700K pointspts_100a table of ~7M points
We will work with the default configuration parameters and just mess with the max_parallel_workers_per_gather at run-time to turn parallelism on and off for comparison purposes.
When max_parallel_workers_per_gather is set to 0, parallel plans are not an option.
max_parallel_workers_per_gathersets the maximum number of workers that can be started by a single Gather or Gather Merge node. Setting this value to 0 disables parallel query execution. Default 2.
Before running tests, make sure you have a handle on what your parameters are set to: I frequently found I accidentally tested with max_parallel_workers set to 1, which will result in two processes working: the leader process (which does real work when it is not coordinating) and one worker.
show max_worker_processes;
show max_parallel_workers;
show max_parallel_workers_per_gather;Aggregates
Behaviour for aggregate queries is still good, as seen in PostgreSQL 10 last year.
SET max_parallel_workers = 8;
SET max_parallel_workers_per_gather = 4;
EXPLAIN ANALYZE
SELECT Sum(ST_Area(geom))
FROM pd;Boom! We get a 3-worker parallel plan and execution about 3x faster than the sequential plan.
Scans
The simplest spatial parallel scan adds a spatial function to the target list or filter clause.
SET max_parallel_workers = 8;
SET max_parallel_workers_per_gather = 4;
EXPLAIN ANALYZE
SELECT ST_Area(geom)
FROM pd; Unfortunately, that does not give us a parallel plan.
The ST_Area() function is defined with a COST of 10. If we move it up, to 100, we can get a parallel plan.
SET max_parallel_workers_per_gather = 4;
ALTER FUNCTION ST_Area(geometry) COST 100;
EXPLAIN ANALYZE
SELECT ST_Area(geom)
FROM pd Boom! Parallel scan with three workers. This is an improvement from PostgreSQL 10, where a spatial function on the target list would not trigger a parallel plan at any cost.
Joins
Starting with a simple join of all the polygons to the 100 points-per-polygon table, we get:
SET max_parallel_workers_per_gather = 4;
EXPLAIN
SELECT *
FROM pd
JOIN pts_100 pts
ON ST_Intersects(pd.geom, pts.geom);
In order to give the PostgreSQL planner a fair chance, I started with the largest table, thinking that the planner would recognize that a “70K rows against 7M rows” join could use some parallel love, but no dice:
Nested Loop
(cost=0.41..13555950.61 rows=1718613817 width=2594)
-> Seq Scan on pd
(cost=0.00..14271.34 rows=69534 width=2554)
-> Index Scan using pts_gix on pts
(cost=0.41..192.43 rows=232 width=40)
Index Cond: (pd.geom && geom)
Filter: _st_intersects(pd.geom, geom)
As with all parallel plans, it is a nested loop, but that’s fine since all PostGIS joins are nested loops.
First, note that our query can be re-written like this, to expose the components of the spatial join:
EXPLAIN
SELECT *
FROM pd
JOIN pts_100 pts
ON pd.geom && pts.geom
AND _ST_Intersects(pd.geom, pts.geom);The default cost of _ST_Intersects() is 100. If we adjust it up by a factor of 100, we can get a parallel plan.
ALTER FUNCTION _ST_Intersects(geometry, geometry) COST 10000;Can we achieve the same affect adjusting the cost of the && operator? The && operator could activate one of two functions:
geometry_overlaps(geom, geom)is bound to the&&operatorgeometry_gist_consistent_2d(internal, geometry, int4)is bound to the 2d spatial index
However, no amount of increasing their COST causes the operator-only query plan to flip into a parallel mode:
ALTER FUNCTION geometry_overlaps(geometry, geometry) COST 1000000000000;
ALTER FUNCTION geometry_gist_consistent_2d(internal, geometry, int4) COST 10000000000000;So for operator-only queries, it seems the only way to force a spatial join is to muck with the parallel_tuple_cost parameter.
Costing PostGIS?
A relatively simple way to push more parallel behaviour out to the PostGIS user community would be applying a global increase of PostGIS function costs. Unfortunately, doing so has knock-on effects that will break other use cases badly.
In brief, PostGIS uses wrapper functions, like ST_Intersects() to hide the index operators that speed up queries. So a query that looks like this:
SELECT ...
FROM ...
WHERE ST_Intersects(A, B)Will be expanded by PostgreSQL “inlining” to look like this:
SELECT ...
FROM ...
WHERE A && B AND _ST_Intersects(A, B)The expanded version includes both an index operator (for a fast, loose evaluation of the filter) and an exact operator (for an expensive and correct evaluation of the filter).
If the arguments “A” and “B” are both geometry, this will always work fine. But if one of the arguments is a highly costed function, then PostgreSQL will no longer inline the function. The index operator will then be hidden from the planner, and index scans will not come into play. PostGIS performance falls apart.
This isn’t unique to PostGIS, it’s just a side effect of some old code in PostgreSQL, and it can be replicated using PostgreSQL built-in types too.
It is possible to change current inlining behaviour with a very small patch but the current inlining behaviour is useful for people who want to use SQL wrapper functions as a means of caching expensive calculations. So “fixing” the behaviour PostGIS would break it for some non-empty set of existing PostgreSQL users.
Tom Lane and Adreas Freund briefly discussed a solution involving a smarter approach to inlining that would preserve both the ability inline while avoiding doing double work when inlining expensive functions, but discussion petered out after that.
As it stands, PostGIS functions cannot be properly costed to take maximum advantage of parallelism until PostgreSQL inlining behaviour is made more tolerant of costly parameters.
Conclusions
-
PostgreSQL seems to weight declared cost of functions relatively low in the priority of factors that might trigger parallel behaviour.
- In sequential scans, costs of 100+ are required.
- In joins, costs of 10000+ are required. This is suspicious (100x more than scan costs?) and even with fixes in function costing, probably not desireable.
-
Required changes in PostGIS costs for improved parallelism will break other aspects of PostGIS behaviour until changes are made to PostgreSQL inlining behaviour…