17 Dec 2007
The news that a third center-line road data provider is starting up is very interesting. In an interview with Directions they are relatively closed-lipped about why they think they can compete with the big boys, but a good guess can be had by looking at their earlier news releases. This not a road mapping company, this is a computer vision company. Presumably the liberal application of computer vision allows them to combine their GPS and intertial data with road sign readings to build out full navigation-restricted data without a heavy manual data post-processing step.
That still leaves the tricky aspect of actually driving their cars down every street in the country, and I wonder what mapping source they used to ensure they weren’t missing any. The mathematics of driving every road in the country are also daunting: 4 million miles of roads in the USA, at an average speed of 20 miles per hour, for 8 hours a day, implies 25,000 days of driving! Or $2M using $10/hour drivers, plus the capital cost (at least $5M) of the 70+ vehicles needed to do the thing in about a year.
On the other hand, given that Nokia just paid $8B for NavTeq, the cost of entry into this marketplace is incredibly low — $20M maybe? I think I’m in the wrong business, time to hit the road!
07 Dec 2007
Collaring can pre-exist in images that have been masked prior to delivery, or can be generated by the process of re-projection, as the spare pixels in the target system get filled in with “no data” values.
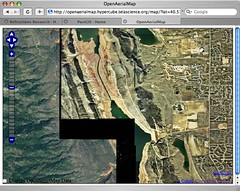
Sean uploaded some data from his home town of Fort Collins, and the OAM process to reproject it into the global OAM scheme (lat/lon?) collared it, which shows up at the edges of the data.
There are some GDAL tricks to make the collars transparent, but if there’s some blank “no data” areas in the source imagery, it is hard to avoid it. OSSIM has some more advanced mosaicking capabilities that might fit the OAM processing needs better than GDAL.
05 Dec 2007
Allow me to echo Peter Batty’s sentiment about this silly post in All Points Blog on neography and real “GIS”.
Speaking at Korem’s Geodiffusion conference, Pitney Bowes Software president, Mike Hickey, struck a resonant chord when he explained that “the explosion of Neogeography is driving awareness [and] collaborative data consolidation [but it] isn’t GIS.” Hickey explained that while neogeography is focused on “Where” there is no data creation and no spatial analysis, an essentially visually useful concept that has helped “cross the chasm from early adopters to an early majority.”
– All Points Blog
As a former vendor himself, I’m sure Peter recognizes the core appeal here is to the emotional hind-brain of all the suckers^H^H^H^H^H^H^Hcustomers who have already dropped coin for MapInfo software. Hickey is reassuring his customers that neography is (like open source software) fundamentally inferior to real “GIS” because it doesn’t cost enough money.
MapInfo makes Real GIS Software™, and you can tell, because it has a Real Big Pricetag. I know Oracle must be a Great Database®, because it costs a cool 1/4 million dollars to deploy on a 20 thousand dollar dual-quad server.
Try to remember folks, it’s not how big your tool is, it’s what you do with it that counts.
29 Oct 2007
If you word things right, even pre-existing concepts can be re-packaged as bright original ideas. Google has filed a patent on an indexing method that is nothing but a specialization of a quad-tree, and a packing of level/row/column information into a 64-bit address space.
The specialization of quad-tree is to always use powers-of-two: cut your parents into four identical children; ensure the children are at a scale exactly half that of the parents. This yields nice behavior in the row/column, you can traverse to the parent row/column of a cell just be dividing the current row/column by two.
The packing of the information into a cell id is not completely clearly explained, because there is some talk of compacting and stop bits, to fit 31 levels, but even without compacting a 64-bit space can hold 29 levels quite easily (5 bits of level information, 29 bits of row address, 29 bits of column address).
I am a bit incredulous at the implied assertion that no one thought of chopping up the map of the world in descending powers-of-two before. The specific claims about the packing method might indeed be “original” but in such a trivial way as to be unimportant.
The whole process of software patenting reminds me of the historical acts of enclosure in England.
They hang the man, and flog the woman,
That steals the goose from off the common;
But let the greater villain loose,
That steals the common from the goose.
– Oliver Goldsmith
18 Oct 2007
Wow, what a great synthesis of larger FOSS4G philosophies and culture! Danny de Vries absolutely nails it, on a whole bunch of topics, including interoperability:
What makes open-source so different from a corporate system like ESRI is its fundamental interest in building software according to universal standards. This in contrast to the strategic interest of any closed, corporate system to somehow make users reliant on their system alone.



