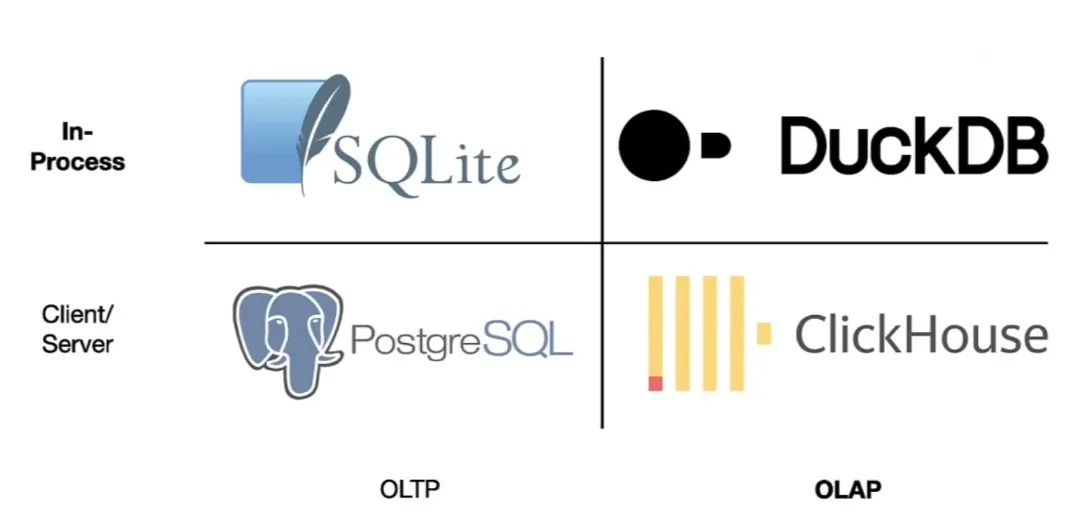
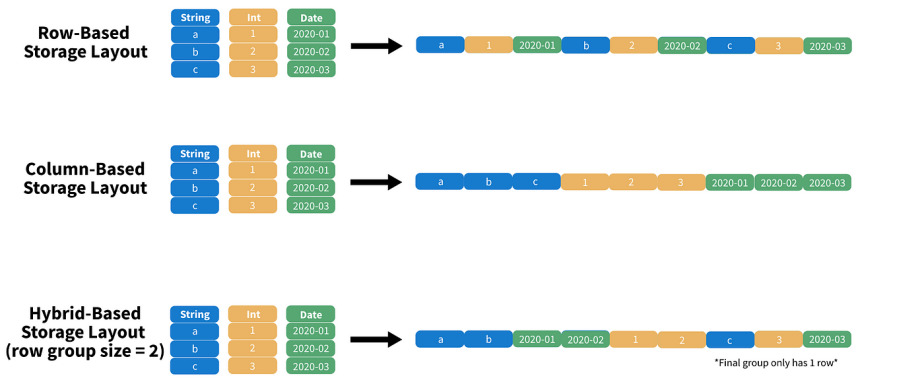
For a long time, a big constituency of users of PostGIS has been people with large data analytics problems that crush their desktop GIS systems. Or people who similarly find that their geospatial problems are too large to run in R. Or Python.
These are data scientists or adjacent people. And when they ran into those problems, the first course of action would be to move the data and parts of the workload to a “real database server”.
This all made sense to me.
But recently, something transformative happened – Crunchy Data upgraded my work laptop to a MacBook Pro.
Suddenly a GEOS compile that previously took 20 minutes, took 45 seconds.
I now have processing power on my local laptop that previously was only available on a server. The MacBook Pro may be a leading indicator of this amount of power, but the trend is clear.
What does that mean for default architectures and tooling?
Well, for data science, it means that a program like DuckDB goes from being a bit of a curiosity, to being the default tool for handling large data processing workloads.
What is DuckDB? According to the web site, it is “an in-process
SQL OLAP database management system”. That doesn’t sound like a revolution in data science (it sounds really confusing).
But consider what DuckDB rolls together:
A column-oriented processing engine that makes the most efficient possible use of the processors in modern computers. Parallelism to ensure all CPUs are made use of, and low-level optimizations to ensure each tick of those processors pushes as much data through the pipe as possible.
Wide ranging support for different data formats, so that integration can take place on-the-fly without requiring translation or sometimes even data download steps.
Having those things together makes it a data science power tool, and removes a lot of the prior incentive that data scientists had to move their data into “real” databases.
When they run into the limits of in-memory analysis in R or Python, they will instead serialize their data to local disk and use DuckDB to slam through the joins and filters that were blowing out their RAM before.
They will also take advantage of DuckDB’s ability to stream remote data from data lake object stores.
What, stream multi-gigabyte JSON files? Well, yes that’s possible, but it’s not where the action is.
The CPU is not the only laptop component that has been getting ridiculously powerful over the past few years. The network pipe that connects that laptop to the internet has also been getting both wider and lower latency with every passing year.
As the propect of streaming data for analysis has come into view, the formats for remote data have also evolved. Instead of JSON, which is relatively fluffy, and hard to efficiently filter, the Parquet format is becoming a new standard for data lakes.
Parquet is a binary format, that organizes the data into blocks for efficient subsetting and processing. A DuckDB query to a properly organized Parquet time series file might easily pull only records for 2 of 20 columns, and 1 day of 365, reducing a multi-gigabyte download to a handful of megabytes.
The huge rise in available local computation, and network connectivity is going to spawn some new standard architectures.
Imagine a “two tier” architecture where tier one is an HTTP object store and tier two is a Javascript single page app? The COG Explorer has already been around for a few years, and it’s just such a two tier application.
(For fun, recognize that an architecture where the data are stored in an access-optimized format, and access is via primitive file-system requests, while all the smarts are in the client-side visualization software is… the old workstation GIS model. Everything old is new again.)
The technology is fresh, but the trendline is pretty clear. See Kyle Barrron’s talk about GeoParquet and DeckGL for a taste of where we are going.
Meanwhile, I expect that a lot of the growth in PostGIS / PostgreSQL we have seen in the data science field will level out for a while, as the convenience of DuckDB takes over a lot of workloads.
The limitations of Parquet (efficient remote access limited to a handful of filter variables being the primary one, as will cojoint spatial/non-spatial filter and joins) will still leave use cases that require a “real” database, but a lot of people who used to reach for PostGIS will be reaching for Duck, and that is going to change a lot of architectures, some for the better, and some for the worse.
As a young man, I had a lot of ambition to climb the greasy pole, to get to the “top” of this heap we call a “career”, and as time went on I started doing little explorations of the career histories of people who made it to that apex corporate title, the “CEO”.
It is worth doing this because, by and large, our society is run by people who either have been CEOs or who have come very close. Pull lists of boards of both private and public institutions and you will see a lot of people who have ascended to the top of large institutions before moving into governance. These are the people who determine the direction of our society, by and large.
And how have they gotten there? Through a surprisingly small number of routes, that are all highly path dependent.
If you spend some time exploring the employment histories of corporate leaders, you’ll find really just a couple archetypes.
The Long-term Corporate Climber
By far the most common pattern is for a future CEO to find an entry- or mid-level position in a large organization, and then work at that one organization for 15 to 25 years, ascending the ranks.
Once they get to just below the CEO, they either leap to a CEO position at another firm, or finally ascend to the CEO position of their originating organization.
Darren Woods, CEO of ExxonMobile, spent 25 years working his way to the top of Exxon.
Ginny Rometty, former CEO of IBM, spent 25 years working her way to the top of IBM.
Jim Farley, CEO of Ford, actually did his important climbing (from entry level to upper management) over 17 years at Lexus, then spent another 13 years at Ford completing the climb to CEO through a sequence of high level regional jobs.
David Hutchens the CEO of our local gas utility, spent 26 years climbing the rungs of Tuscon Electric.
I was spurred to write about this topic today when I learned that EDB has a new CEO (what?!), Kevin Dallas, who (wait for it), spent 24 years climbing the greasy pole at Microsoft, before being tapped for his first CEO gig in 2020.
Speaking of Microsoft, even corporate leadership savant Satya Nadella started as an entry level engineer in Microsoft, taking the CEO slot in 2014 after 22 years of slogging upwards.
In the main, the way to become a CEO (of a large organization) is to get yourself a job in a large organization early in your career, so you can accumulate the experience and contacts necessary to be considered a viable candidate later in your career.
The path dependence is kind of obvious. If you spend your early career on something else, by the time you get into a large organization you will be starting too far down the heirarchy to reach the top before your career tapers off.
To many, the surprising thing about these career profiles is how rarely there are mid-career jumps between corporations. Probably this is because people under-estimate the power of social networks.
Your reputation for “getting things done”, the density of people who find you charming, the employees and hangers on who benefit from your rise in the organization, they are all highest in one place: the place you already work. Moving laterally in mid-career to a new organization instantly resets your accumulated social capital to zero.
The Founder or Early Hire
One exception to the rule is the founder of a company that grows to a scale sufficient to be considered comparable to existing institutions.
This is, as you can imagine, quite rare.
In the “wow that’s insane” founder category: Bill Gates, Steve Jobs, Mark Zuckerberg, Sara Blakely.
Or the “locally known but still huge” founder category: Ryan Holmes (Hootsuite), Chip Wilson (Lululemon), Stewart Butterfield (Slack, Flickr), James Pattison (Pattison Group), Dennis Washington (Seaspan).
In the tech space, there’s also a lot of early hires, who necessarily progressed quite quickly through the “ranks” as the company they had lucked into exploded in size.
Erik Schmidt, who rode Sun Microsystems rocket to senior management before finding CEO roles at Novell and Google.
Steve Balmer, who… do I need to even say?
Sundar Pichai, who joined Google in 2004 and held on to become CEO as the founders burned out.
The Well Connected
This is an interesting third category, which is difficult to join, but is very much real – knowing people who will elevate you early on.
Like, former Treasury Secretary Tim Geithner had on the one hand, a kind of conventional “grind it out” career working his way up the ranks of the senior federal civil service. But on the other hand, the roles he was in, right from the start were quite high level. How did he manage that? He was recommended to his first job out of college at Kissinger Associates, by the Dean of his faculty at Johns Hopkins. From there he met lots of powerful people who would vouch for his brilliance, and away he went. Now, it surely helped that he was brilliant! But, the connections were necessary too.
I checked out the career history of Jamie Dimon, CEO of JP Morgan, expecting to find a long slog at a major financial institution, but it turns out Dimon got an early boost into leadership, through his connection to Sandy Weill, who recruited him to American Express. And how did Weill know Dimon? Dimon’s mother knew Weill and got Dimon hired for a summer job with him. Again, it surely helped that Dimon was sharp as a tack! But, without his mom…
In lots of cases, this category is fully subsumed in the first. Anyone who grinds up a corporate heirarchy will find boosters and mentors who will in turn help them get ahead. Often a senior leader gets a lot of help from a talented junior and they ascend the heirarchy in parallel. Being the “assistant to the President” might make you officially lower on the totem pole than the CFO, but unofficially and in terms of career advancement… that can be another story altogether.
Advice?
Despite my long-time desire to climb the greasy pole, I have never worked for an instution large enough to have any serious opportunities to climb, and have finally achieved a zen calm about career. By and large my career has been something that happened to me, not something I planned, and that colors my perceptions a lot.
First jobs lead to first connections, and first connections determine what paths open up as you move on to second and third jobs. Path dependence in career progression is huge. Probably the most important moment is early career, getting into an institution or industry that is poised for growth and change.
It’s possible to rise in an older, established institutions, but my impression is that it’s more of a knife fight. I don’t think the alternate universe Steve Balmer who started in sales at IBM would have risen to be a CEO.
Far and away the most important thing you can amass, at any career stage, is connections. Take every opportunity to meet new people, and find people and topics that stimulate your curiosity. If what you are doing is boring or unpleasant, it’s never going to matter what your title is, or how high up the pole you are.
Preparing the keynote for FOSS4G North America this year felt particularly difficult. I certainly sweated over it.
Audience was a problem. I wanted to talk about my usual thing, business models and economics, but the audience was going to be a mash of people new to the topic and people who has seen my spiel multiple times.
Length was a problem. Out of an excess of faith in my abilities, the organizers gave me a full hour long slot! That is a very long time to keep people’s attention and try to provide something interesting.
The way it all ended up was:
Cadging some older content from keynotes about business models, to bring new folks up to speed.
Mixing in some only slightly older content about cloud models.
Adding in some new thoughts about the way everyone can work together to make open source more sustainable (or at least less extractive) over the long term.
Here’s this year’s iteration.
The production of this kind of content is involved. The goal is to remain interesting over a relatively long period of time.
I have become increasingly opinionated about how to do that.
No freestyling. Blathering over bullet points is unfair to your audience. The aggregate time of an audience of 400 is very large. 5 minutes of your “um” and “ah” translates into 33 hours of dead audience time.
Get right to it. No mini-resume, no talking about your employer (unless you are really sneaky about it, like me 😉), this is about delivering ideas and facts that are relevant to the audience. Your introducer can handle your bona fides.
Have good content. The hardest part! (?) Do you have something thematic you can bookend the start and end with? Are there some interesting facts that much of the audience does not know yet? Are there some unappreciated implications? This is, presumably, why you were asked to keynote, so hopefully not too, too hard. This is the part that I worry over the most, because I really have no faith that what I have to say is actually going be interesting to an audience, no matter how much I gussy it up.
Work from a text. The way to avoid blather is to know exactly what you are going to say. At 140 words-per-minute speaking pace, a 55 minute talk is 7700 words, which coincidentally (not) is exactly how long my keynote text is.
Write a speech, not an article. You will have to say all those words! Avoid complicated sentence constructions. Keep sentences short. Take advantage of parallel constructions to make a point, drive a narrative, force a conclusion. (see?) Repeat yourself. Repeat yourself.
Perform, don’t read. Practice reading out loud. Get used to leaving longer gaps and get comfortable with silence. Practice modulating your voice. Louder, softer. Faster, slower. Drop. The. Hammer. Watch a gifted speaker like Barack Obama deliver a text. He isn’t ad libbing, he’s performing a prepared text. See what he does to make that sound spontaneous and interesting.
Visuals as complements, not copies. Your slides should complement and amplify your content, not recapitulate it. In the limit, you could do all-text slides, which just give the three-word summary of your current main point. (This classic Lessig talk is my favourite example.)
Visuals as extra channel. Keep changing up the visual. Use the slide notes space to get a feel for how long each slide should be up. (Hint, about 50 words on average.) Keeping slide duration low also helps in terms of using the per-slide speaker notes as low-end teleprompter (increase notes font size! reduce slide preview size!) from which you deliver your performance.
I originally started scripting talks because it allowed me to smooth out the quality of my talks. With a script, it wasn’t a crapshoot whether I had a good ad lib delivery or a bad one, I had a nice consistent level. From there, leveraging up to take advantage of the format to increase the talk quality was a natural step. Speakers like Lessig and Damian Conway remain my guide posts.
If you liked the keynote video and want to use the materials, the slides are available here under CC BY.
TL;DR: geospatial data tends to be more “visible” to end user clients, so communicating change to multiple clients in real time can be useful for “common operating” situations.
Last month I was invited to give a keynote talk at the CUGOS Spring Fling, a delightful gathering of “Cascadia Users of Open Source GIS” in Seattle. I have been speaking about open source economics at FOSS4G conferences more-or-less every two years, since 2009, and took this opportunity to somewhat revisit the topics of my 2019 FOSS4GNA keynote.