12 May 2008
My annoyance at learning that OS/X 10.5 doesn’t really support gprof has turned into ecstasy at finding the wholly superior Shark profiler that comes with XCode.
Unlike gprof, Shark doesn’t require that you compile with special profiling flags, it can run on unaltered binaries. In fact, Shark doesn’t even require that you run it against any binary in particular! You can run it against everything on your system, then view the profile of any process post-facto.
I just did a profile of Mapserver running as a FastCGI process, just by running some load against Mapserver and letting Shark collect statistics on all processes at once. Then I pick the mapserv.fcgi process from the sample data, and voila!
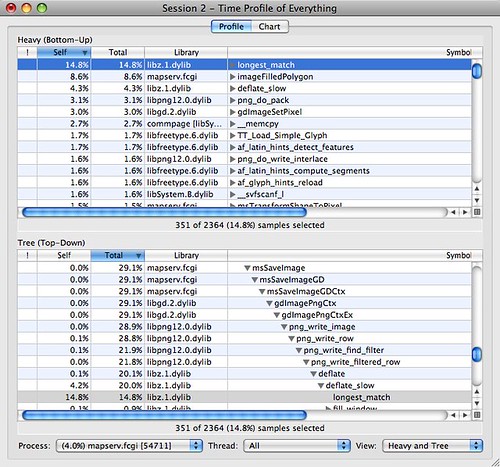
I can see that the most costly small function is longest_match, from the bottom-up view at the top, and that it is called in the image saving routines, in the top-down view at the bottom. Good news, Mapserver is so efficient that the biggest cost is compressing the output image.
Even cooler, I can flip to chart view and see what the CPUs were doing throughout the sample period. The blue spikes are mapserv.fcgi calls.
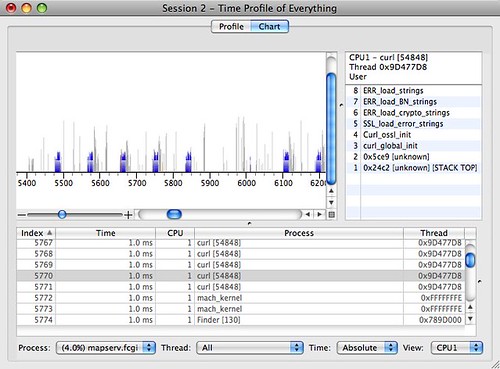
Zoom into one of those, and we can see the CPU ticks through one map draw, including the kernel (the red bit) taking a slice out. End to end, Mapserver is taking about 15ms to draw this particular map.
In addition to the “Time Profile” mode I’m showing here, there’s also a “Java Time Profile”. I wonder if Java developers can make use of this excellent tool too?
12 May 2008
A post for posterity.
OK, so you want to run FastCGI on OS/X 10.5, how does that work? If you’ve just followed the directions and used your usual UNIX skillz, you’ll have dead-ended on this odd error:
httpd: Syntax error on line 115 of /private/etc/apache2/httpd.conf: Cannot load /usr/libexec/apache2/mod_fastcgi.so into server: dlopen(/usr/libexec/apache2/mod_fastcgi.so, 10): no suitable image found. Did find:\n\t/usr/libexec/apache2/mod_fastcgi.so: mach-o, but wrong architecture
This is the architecture of your DSO not matching the x86_64 architecture of the build shipped with OS/X. So we must build with the correct flags in place.
Here’s the steps from scratch.
curl http://www.fastcgi.com/dist/mod_fastcgi-2.4.6.tar.gz > mod_fastcgi-2.4.6.tar.gz
tar xvfz mod_fastcgi-2.4.6.tar.gz
cd mod_fastcgi-2.4.6
cp Makefile.AP2 Makefile
Now edit Makefile and change top_dir to /usr/share/httpd and add a line CFLAGS=-arch x86_64.
make
sudo cp .libs/mod_fastcgi.so /usr/libexec/apache2
Now edit /private/etc/apache2/httpd.conf and add a line LoadModule fastcgi_module libexec/apache2/mod_fastcgi.so. Run sudo apachectl restart and you are now loaded. You’ll need to enable FastCGI for your applications as described in the documentation.
02 May 2008
I spent the morning yesterday at an Oracle Technical Session, lots of government employees and contractors crammed into a ballroom listening to Oracle reps talk about the latest-and-greatest offerings from the beast.
The best part was, after a one hour presentation on “Oracle Fusion Middleware”, by quite a polished speaker, he asks for questions, and someone says:
“Thanks for your presentation, but, I still have no idea what Fusion Middleware does.”
Ouch.
Fair comment, too, the presentation was all market-speak, how data was “integrated”, decisions “made more quickly”, and so on. Clarity is not aided by the fact that “Oracle Fusion Middleware” is itself a suite of a dozen different bits.
To quote Oracle’s web site, a “portfolio of customer-proven software that spans from portals and process managers to application infrastructure, developer tools, and business intelligence”.
Some  cone-head in the Oracle marketing department has decided that all these bits and pieces will be easier to sell if they are all wrapped under one product brand, “Fusion Middleware”. But really, pretending it is all one thing has made the product too big to explain.
cone-head in the Oracle marketing department has decided that all these bits and pieces will be easier to sell if they are all wrapped under one product brand, “Fusion Middleware”. But really, pretending it is all one thing has made the product too big to explain.
What does it do? Everything. Nothing. It depends.
It brings to mind The Elephant and the Blind Men.
30 Apr 2008
After an enlightening start picking up C, I spent a fair bit of time in April working on the Mapserver code base. All my April work is now committed, so it will be available in the upcoming 5.2 release.

Large shapefile performance
This been a problem for as long as Mapserver has been around, but Mapserver has been so damn fast that for the most part the performance fall-off as files got larger was ignored (if you can render your map in 0.12s on a 2M record file, that’s still pretty acceptable).
However, during FOSS4G2007, Brock Anderson reported that Mapserver was actually several times slower than Geoserver for the particular use case of rendering a small map off a large file.

This could not be borne.
The problem turned out to be the way Mapserver handled the SHX file, loading it all into memory for each render. For a very large file, loading the whole SHX file just to pull less than 1% of the records out is a very bad performance bargain. So I re-wrote the SHX handling to lazily load just the bits of the SHX file needed for the features being rendered.
A secondary problem was that Mapserver kept the list of “features to draw” in a bitmap with as many entries as the shape file had records. Then it iterated through that list, at least twice for each render. Counting to several million twice when you only want a couple hundred features is a waste of time. Replacing the bitmap would have been a lot of work, so I replaced the iteration with one about 10 times faster.
The net result was a several-times improvement in speed for small maps rendered on big files. My reference render of 20 features from 1.8M went from a respectable 0.120s to a screaming 0.037s.
Tile-based map access
“How do I put my Mapserver layers into Google Maps?”
A fair question. Here’s this great mapping user interface, and this great map renderer, they should go together like chocolate and peanut butter. It’s possible to do with a relatively thin script on top of Mapserver, but requires some extra configuration steps.

This upgrade cuts the steps down to:
- author map file; and
- author Google Maps HTML page.
See the tile mode howto for some examples. It boils down to using the GTileLayer and setting the tileUrlTemplate to point at a tile-enabled Mapserver.
WMS client URL encoding
These were minor patches, but issues that had been bugging me for a while.
The WMS client URL encoding brings Mapserver intro strict compliance with the WMS specification and that will allow it to work with strict servers, of which the ER Mapper Image Server is one.
HTTP Cache-control headers
The HTTP patch allows the user to configure Mapserver to send a Cache-control: max-age=nnnn header with WMS responses. For clients like OpenLayers, that fetch images in a tiled manner, this should hopefully promote a more cache-friendly behavior, and faster performance.
28 Apr 2008
 And my publicist and stylist, oh and Mom and Dad…
And my publicist and stylist, oh and Mom and Dad…
But mostly Howard Butler for nominating me and the rest of the Mapserver PSC for accepting me as a Mapserver committer. I guess my crazy ideas and cockeyed schemes didn’t scare them off!
You like me! You really like me!



