“How can I get paid to work on this cool open source project?”
Once upon a time, it felt like most discussions about open source were predicated on answering this question. Developers fell in love with, or created, some project or other, but found themselves working on it in their spare time. If only there was some way to monetize their labour of love!
From that complaint, a score of (never quite satisfactory) models were spawned.
Pure consulting, which depends on a never-ending supply of enhancements and updates, usually to the detriment of core maintainance.
Professional support, which depends on a deep enough market of potential enterprises, and a sense of “deployment risk” large enough to open wallets.
Open core, which invests in the open source core to promote adoption and hopefully build a sub-population of enterprises that have embedded the project sufficiently to be in the market for add-ons to make things faster/simpler/more integrated.
Relicensing, which leverages adoption of the open source to squeeze conventional licensing revenue out of enterprises that don’t want to accept open source license terms of use.
What all the models above have in common is that they more-or-less require successful adopters to invest effort in the open source project at the center of the model. Adoption of the open source project is an “on ramp” to revenue opportunities, but the operating assumption is that customer will continue using the open source core, so the business has an incentive to invest in the “on ramp”.
In the same way, Oracle provides an “on ramp” to their enterprise product, in the free-as-in-beer Oracle Express. Oracle pays for the development of the on-ramp (it’s just Oracle, after all) and in return (maybe) reaps the reward of eventual migration of users to their paid product.
AWS deliberately does not say Aurora is “PostgreSQL”. They say it is “PostgreSQL compatible”. That’s probably for the best: Aurora is a soft fork of the core PostgreSQL code that replaces big chunks of PostgreSQL storage logic with clever, custom AWS code.
Like AWS PostgreSQL RDS, Aurora is a revenue generating fork of PostgreSQL that uses open source PostgreSQL adoption as an on-ramp for AWS revenue. This would superficially seem to be a similar situation to all the other open source business models, except for one thing: AWS doesn’t have any stake in the success of PostgreSQL per se.
AWS offers RDS versions of all the RDBMS systems, open source and otherwise, and they invest in the core projects accordingly, and fairly: hardly at all. After all, to do otherwise would be to declare a preference.
So the open source communities end up building the on-ramp to AWS paid services as a free gift to AWS.
That’s annoying enough, but it gets uglier, I think, as time goes on.
For now, Aurora tracks the PostgreSQL version fairly well. You can move your app onto Aurora, you can move it back off to RDS, you can move it to Google’s managed PostgresSQL, you can host it yourself on premise or in the cloud.
However, eventually the business expense of maintaining the Aurora code base against a PostgreSQL baseline that is in constant motion will wear on Amazon, and they will start to see places where adding “Aurora only” features will “improve the customer experience”.
At that point, the soft fork will turn into a hard fork, and migrations into Aurora will start to look like a one-way valve.
And the community will still be maintaining the on-ramp to AWS.
Let me pre-empt some of the commentary.
“Free riding is part of the deal!”
Sure it is. AWS isn’t doing anything illegal. They are just taking advantage where they can take advantage.
Similarly, the industries that dumped waste into the Cuyahoga River until it was so polluted it caught fire were no doubt working within the letter of the law.
Free riding is part of the deal.
I hope that all kinds of people and organizations free ride on my open source work, it’s part of the appeal of the work.
I also hope that enlightened self-interest at the very least will lead to one of two outcomes:
That the customers of AWS RDS and (particularly) Aurora recognize that the organization they are paying (AWS) is not adequately supporting the core of they software (PostgreSQL) their operations depend on, and that as a result they are implicitly taking on the associated technical risk of under-investment.
That AWS itself has the foresight to invest directly in the open source on-ramps to their paid cloud deployments, acknowledging that the core software does in fact provide just as much (and maybe even more) value as their impressive cloud infrastructure does.
I think it’s more likely that short term thinking will lead to “AWS only” featuritis and the creation of a one-way valve, even the deliberate downgrading of RDS and on-premise capabilities to drive customers into the arms of Aurora, because: why not?
The logic of enterprise sales is: land, expand, lock-in, and squeeze.
Just because AWS is currently in the land-and-expand phase doesn’t mean they won’t get to the succeeding phases eventually.
When talking to government audiences, I like to point out that the largest national mapping agency in the world resides in a building decorated like a hypertrophic kindergarten, in Mountain View, California. This generally gets their attention.
The second most important year in my career in geospatial was 20051, the year that Google Maps debuted, and began the migration of “maps on computers” from a niche market dominated by government customers to the central pivot of multiple consumer-facing applications.
The echoes of 2005 lasted for several years.
Microsoft quickly realized it was dramatically behind in the space, “MapPoint” being its only spatial product, and went on an acquisitionandR&D spree.
Esri started moving much more quickly into web technology, slavishly aping Google product direction (spinny globes?! yes! JSON on the wire!? yes! tiled basemaps?!? oh yes!) in what must have been an embarassing turn for the “industry leader” in GIS.
Navteq and Teleatlas transitioned quickly from industry darlings (selling data to Google!) to providers of last resort, as more nimble data gatherers took up the previously-unimagineable challenge of mapping the whole world from scratch.
Open source did its usual fast-follower thing, churning out a large number of Javascript-and-map-tiles web components, and pivoting existing rendering engines into tile generators.
A funny thing happened in the shake out, though. Nobody ever caught up to Google. Or even came very close. While Google has abandoned Maps Engine–their foray into “real GIS”–their commitment to core location data, knowing where everything is and what everything is, all the time and in real time, remains solid and far in advance of all competitors.
Probably even before they rolled out the iPhone in 2007 Apple knew they had a “maps problem”. Once they added a GPS chip (a development that was only awaiting a little more battery oomph) they would be beholden to Google for all the directions and maps that made the chip actually useful to phone users.
And so we eventually got the Apple maps debacle of 2012. It turns out, building a global basemap that is accurate and includes all the relevant details that users have come to expect is really really really hard.
In an excellent article on the differences between Google and Apple’s maps, Justin O’Beirne posited:
Google has gathered so much data, in so many areas, that it’s now crunching it together and creating features that Apple can’t make—surrounding Google Maps with a moat of time.
Even the most well-funded and motivated competitors cannot keep up. Microsoft came the closest early on with Bing Maps, but seems to have taken their foot off the gas, in acknowledgement of the fact that they cannot achieve parity, let alone get ahead.
And so what? So what if Google has established Google Maps as a source of location data so good and so unassailable that it’s not worth competing?
Well, it sets up an interesting future dynamic, because the competitive advantage those maps provide is too large to leave unchallenged.
Apple cannot afford to have their location based devices beholden to Google–a direct competitor now via Android–so they have continued to invest heavily in maps. They’ve been a lot quieter about it after the debacle, but they haven’t given up.
Amazon AWS is the unchallenged leader in cloud computing, but Google wants a bigger piece of the cloud computing pie, and they are using Google Maps as a wedge to pull customers into the Google Cloud ecosystem. I have heard of multiple customers who have been wooed via combined Maps + Cloud deals that offer discounted Cloud pricing on top of Maps contracts. Why not put it all in one data centre?
Salesforcehas just purchased Tableau, pulling one of the largest BI companies into the largest enterprise cloud company. Analytics has a lower need for precise location data, but Salesforce customers will include folks who do logistics and other spatial problems requiring accurate real-time data.
Someone is going to take another run at Google, they have to. My prediction is that it will be AWS, either through acquisition (Esri? Mapbox?) or just building from scratch. There is no doubt Amazon already has some spatial smarts, since they have to solve huge logistical problems in moving goods around for the retail side, problems that require spatial quality data to solve. And there is no doubt that they do not want to let Google continue to leverage Maps against them in Cloud sales. They need a “good enough” response to help keep AWS customers on the reservation.
How will we know it’s happening? It might be hard to tell from outside the Silicon Valley bubble. Most of the prominent contributors to the New Mapping Hegemony live behind the NDA walls of organizations like Google and Apple, but they are the kinds of folks Amazon will look to poach, in addition to members of Microsoft’s Bing team (more conveniently already HQ’ed in Seattle).
I think we’re due for another mapping space race, and I’m looking forward to watching it take shape.
1. The most important event of my geospatial career was the release of the iPhone 3GS with a GPS chip as a standard component.
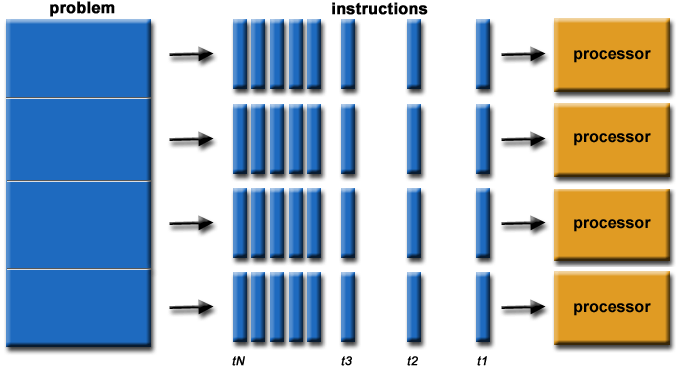
In my last post I demonstrated that PostgreSQL 12 with PostGIS 3 will provide, for the first time, automagical parallelization of many common spatial queries.
This is huge news, as it opens up the possibility of extracting more performance from modern server hardware. Commenters on the post immediately began conjuring images of 32-core machines reducing their query times to miliseconds.
So, the next question is: how much more performance can we expect?
To investigate, I acquired a 16 core machine on AWS (m5d.4xlarge), and installed the current development snapshots of PostgreSQL and PostGIS, the code that will become versions 12 and 3 respectively, when released in the fall.
How Many Workers?
The number of workers assigned to a query is determined by PostgreSQL: the system looks at a given query, and the size of the relations to be processed, and assigns workers proportional to the log of the relation size.
For parallel plans, the “explain” output of PostgreSQL will include a count of the number of workers planned and assigned. That count is exclusive of the leader process, and the leader process actually does work outside of its duties in coordinating the query, so the number of CPUs actually working is more than the num_workers, but slightly less than num_workers+1. For these graphs, we’ll assume the leader fully participates in the work, and that the number of CPUs in play is num_workers+1.
Forcing Workers
PostgreSQL’s automatic calculation of the number of workers could be a blocker to performing analysis of parallel performance, but fortunately there is a workaround.
Tables support a “storage parameter” called parallel_workers. When a relation with parallel_workers set participates in a parallel plan, the value of parallel_workers over-rides the automatically calculated number of workers.
ALTERTABLEpdSET(parallel_workers=8);
In order to generate my data, I re-ran my queries, upping the number of parallel_workers on my tables for each run.
Setup
Before running the tests, I set all the global limits on workers high enough to use all the CPUs on my test server.
I tested two kinds of queries: a straight scan query, with only one table in play; and, a spatial join with two tables. I used the usual queries from my annual parallel tests.
EXPLAINANALYZESELECTSum(ST_Area(geom))FROMpd;
Scan performance improved well at first, but started to flatten out noticably after 8 cores.
Workers
1
2
4
8
16
Time (ms)
318
167
105
62
47
The default number of CPUs the system wanted to use was 4 (1 leader + 3 workers), which is probably not a bad choice, as the expected gains from addition workers shallows out as the core count grows.
Join Performance
The join query computes the join of 69K polygons against 695K points. The points are actually generated from the polygons, so there are precisely 10 points in each polygon, so the resulting relation would be 690K records long.
For unknown reasons, it was impossible to force out a join plan with only 1 worker (aka 2 CPUs) so that part of our chart/table is empty.
Workers
1
2
4
8
16
Time (ms)
26789
-
9371
5169
4043
The default number of workers is 4 (1 leader + 3 workers) which, again, isn’t bad. The join performance shallows out faster than the scan performance, and above 10 CPUs is basically flat.
Conclusions
There is a limit to how much advantage adding workers to a plan will gain you
The limit feels intuitively lower than I expected given the CPU-intensity of the workloads
The planner does a pretty good, slightly conservative, job of picking a realistic number of workers
For the last couple years I have been testing out the ever-improving support for parallel query processing in PostgreSQL, particularly in conjunction with the PostGIS spatial extension. Spatial queries tend to be CPU-bound, so applying parallel processing is frequently a big win for us.
Initially, the results were pretty bad.
With PostgreSQL 10, it was possible to force some parallel queries by jimmying with global cost parameters, but nothing would execute in parallel out of the box.
With PostgreSQL 11, we got support for parallel aggregates, and those tended to parallelize in PostGIS right out of the box. However, parallel scans still required some manual alterations to PostGIS function costs, and parallel joins were basically impossible to force no matter what knobs you turned.
With PostgreSQL 12 and PostGIS 3, all that has changed. All standard query types now readily parallelize using our default costings. That means parallel execution of:
Parallel sequence scans,
Parallel aggregates, and
Parallel joins!!
TL;DR:
PostgreSQL 12 and PostGIS 3 have finally cracked the parallel spatial query execution problem, and all major queries execute in parallel without extraordinary interventions.
What Changed
With PostgreSQL 11, most parallelization worked, but only at much higher function costs than we could apply to PostGIS functions. With higher PostGIS function costs, other parts of PostGIS stopped working, so we were stuck in a Catch-22: improve costing and break common queries, or leave things working with non-parallel behaviour.
For PostgreSQL 12, the core team (in particular Tom Lane) provided us with a sophisticated new way to add spatial index functionality to our key functions. With that improvement in place, we were able to globally increase our function costs without breaking existing queries. That in turn has signalled the parallel query planning algorithms in PostgreSQL to parallelize spatial queries more aggressively.
Setup
In order to run these tests yourself, you will need:
PostgreSQL 12
PostGIS 3.0
You’ll also need a multi-core computer to see actual performance changes. I used a 4-core desktop for my tests, so I could expect 4x improvements at best.
We will work with the default configuration parameters and just mess with the max_parallel_workers_per_gather at run-time to turn parallelism on and off for comparison purposes.
When max_parallel_workers_per_gather is set to 0, parallel plans are not an option.
max_parallel_workers_per_gather sets the maximum number of workers that can be started by a single Gather or Gather Merge node. Setting this value to 0 disables parallel query execution. Default 2.
Before running tests, make sure you have a handle on what your parameters are set to: I frequently found I accidentally tested with max_parallel_workers set to 1, which will result in two processes working: the leader process (which does real work when it is not coordinating) and one worker.
Boom! We get a 3-worker parallel plan and execution about 3x faster than the sequential plan. This query did not work out-of-the-box with PostgreSQL 11.
Right out of the box, we get a parallel plan! No amount of begging and pleading would get a parallel plan in PostgreSQL 11
Gather
(cost=1000.28..837378459.28 rows=5322553884 width=2579)
Workers Planned: 4
-> Nested Loop
(cost=0.28..305122070.88 rows=1330638471 width=2579)
-> Parallel Seq Scan on pts_100 pts
(cost=0.00..75328.50 rows=1738350 width=40)
-> Index Scan using pd_geom_idx on pd
(cost=0.28..175.41 rows=7 width=2539)
Index Cond: (geom && pts.geom)
Filter: st_intersects(geom, pts.geom)
The only quirk in this plan is that the nested loop join is being driven by the pts_100 table, which has 10 times the number of records as the pd table.
The plan for a query against the pt_10 table also returns a parallel plan, but with pd as the driving table.