TL;DR: If you are using ORDER BY or GROUP BY on geometry columns in your application and you have expectations regarding the order or groups you obtain, beware that PostGIS 2.4 changes the behaviour or ORDER BY and GROUP BY. Review your applications accordingly.
The first operators we learn about in elementary school are =, > and <, but they are the operators that are the hardest to define in the spatial realm.
When is = equal?
For example, take “simple” equality. Are geometry A and B equal? Should be easy, right?
But are we talking about:
A and B have exactly the same vertices in the same order and with the same starting points?
A and B have exactly the same vertices in any order? (see ST_OrderingEquals)
A and B have the same vertices in any order but different starting points?
A has some extra vertices that B does not, but they cover exactly the same area in space? (see ST_Equals)
A and B have the same bounds?
Confusingly, for the first 16 years of its existence, PostGIS used definition 5, “A and B have the same bounds” when evaluating the = operator for two geometries.
However, for PostGIS 2.4, PostGIS will use definition 1: “A and B have exactly the same vertices in the same order and with the same starting points”.
Why does this matter? Because the behavour of the SQL GROUP BY operation is bound to the “=” operator: when you group by a column, an output row is generated for all groups where every item is “=” to every other item. With the new definition in 2.4, the semantics of GROUP BY should be more “intuitive” when used against geometries.
What is > and <?
Greater and less than are also tricky in the spatial domain:
Is POINT(0 0) less than POINT(1 1)? Sort of looks like it, but…
Is POINT(0 0) less than POINT(-1 1) or POINT(1 -1)? Hm, that makes the first one look less obvious…
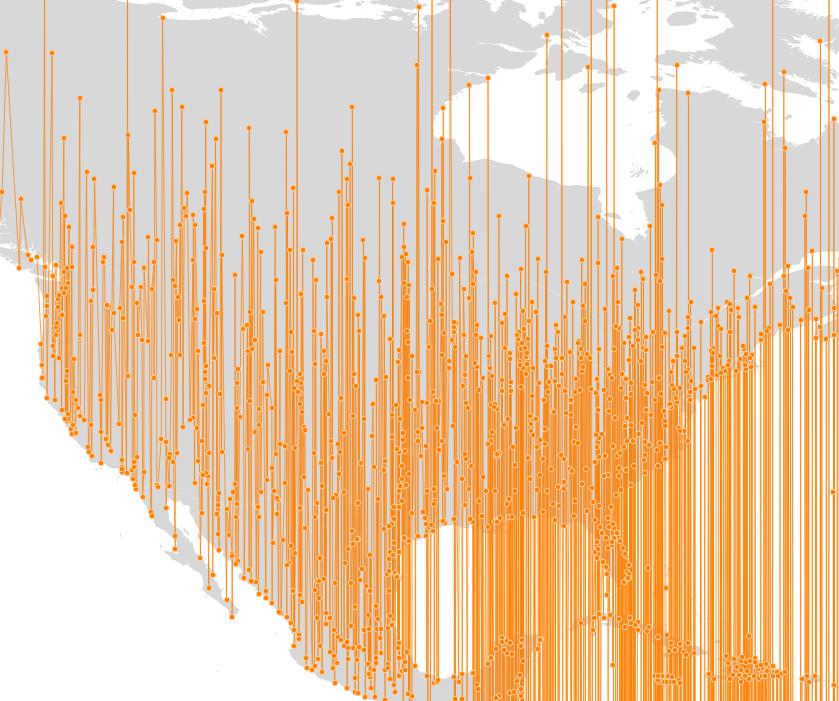
Greater and less than are concepts that make sense for 1-dimensional values, but not for higher dimensions. The “>” and “<” operators have accordingly been an ugly hack for a long time: they compared the minima of the bounding boxes of the two geometries.
If they were sortable using the X coordinate of the minima, that was the sorting returned.
If they were equal in X, then the Y coordinate of the minima was used.
Etc.
This process returned a sorted order, but not a very satisfying one: a “good” sorting would tend to place objects that are near to each other in space, near to each other in the sorted set.
Here’s what the old sorting looked like, applied to world populated places:
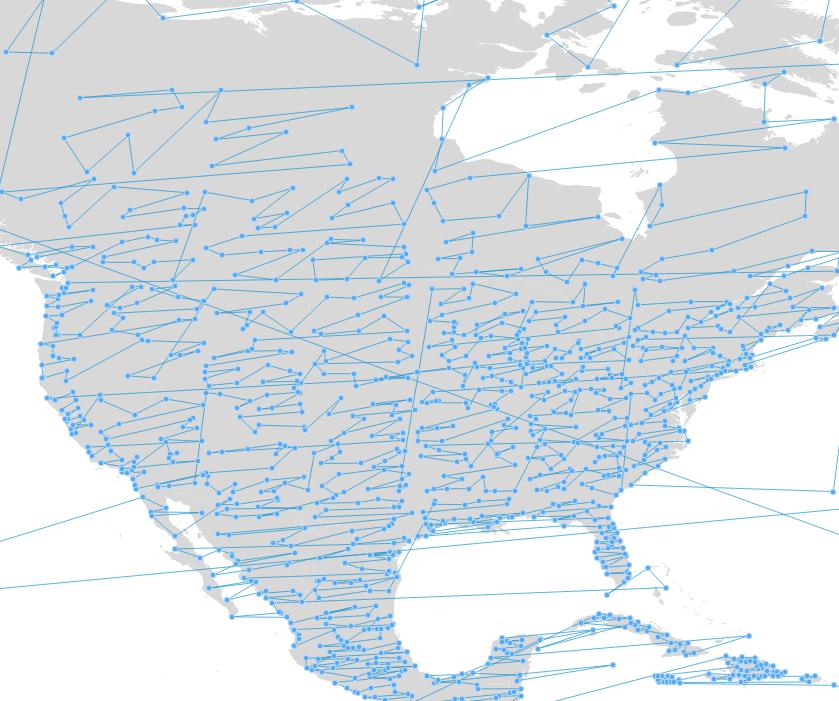
The new sorting system for PostGIS 2.4 calculates a very simple “morton key” using the center of the bounds of a feature, keeping things simple for performance reasons. The result is a sorted order that tends to keep spatially nearby features closer together in the sorted set.
Just as the “=” operator is tied to the SQL GROUP BY operation, the “>” and “<” operators are tied to the SQL ORDER BY operation. The pictures above were created by generating a line string from the populated places points as follows:
Protobuf based output formats for PostGIS, because these are new in PostGIS 2.4 and I haven’t read the commits, might as well get some info straight from the horse’s mouth.
FOSS4G from the Trenches, because the belly of the GIS beast is the local government market, hearing how a practitioner has cracked that most uncrackable and conservative of audiences is very interesting.
Matt Asay asks a question about big data vendors, who are from a business model point-of-view mostly “open source support” companies: HortonWorks as a pure-play and others as open-core and enhanced-oss models.
Is the problem that orgs roll-their-own Spark/etc. (self-support on OSS)? Or maybe most orgs simply aren't doing much (yet) w/ big data? https://t.co/9RGZyEUaV4
My experience has been that open source support companies fall into a market trap. They are supporting good projects, that are popular and widely deployed. It seems like a good place, but the market keeps constantly screwing them.
TL;DR
Potential open source support customers are either:
Small enough to need your expert support, but too small and cheap to supply company-supporting levels of revenue; or,
Large enough to figure it out for themselves, so either take a quick hit of consulting up front or just ignore you and self-support from the start.
Small Customers Suck
Small customers lack the technical wherewithal to use the product unassisted, so they need the support, but they are both highly price sensitive while also being a large drain on support hours (because they really need a lot of help).
You can drop your prices to try and load up a lot of these (“how do we do it? volume!”) but
there are rarely enough fish in the pool to actually run the size of business you need to achieve sustainability.
How large? Large enough that the recurring revenue is enough to support sales, marketing, cost of sales, and a handful of core developers who aren’t tied to support contracts. Not huge, but well beyond the scale of a dev-and-friend-in-basement.
If you do drop your prices to try and bring in the small customers you immediately run into a problem with big customers, who will want big customer questions answered at your small customer price point.
Big Customers Suck, Then Leave
Big customers are frequently drawn to the scaling aspects of open source: deploy 1 instance, deploy 100, the capital cost remains the same.
In theory, there should be room in there for a “one throat to choak” support opportunity for big customers with big deployments, and with competent sales work up front, a good support deal will monetize at least some of the complexity inherent in a large deployment.
In practice, instead of being long term recurring revenue, the big customers end up being short term consulting gigs. A deal is signed, the customer’s team learns the ropes, with lots of support hours from top level devs on your team, and the deployment goes live. Then things settle down and there is a quick scaling back of support payments: year one is great, year two is OK, year three they’re backing away, year four they’re gone.
While there is room to grow a business on this terrain, particularly if the customers are Really Really Big, the constant fade-out of recurring revenue means that the business model is that of a high-end consultancy, not a recurring-revenue support company.
I’ve been adding support for arbitrary CURL options to http-pgsql, and have bumped up against the classic problem with linking external libraries: different functionality in different versions.
CURL has a huge collection of options, and different versions have different support, but for any given options, what versions support it? This turns out to be a fiddly question to answer in general. Each option has availability in the documentation page, but finding availability for every option is a pain.
So, I’ve scraped the documentation and put the answers in a CSV file, along with the hex-encoded version number that CURL exposes in #define LIBCURL_VERSION_NUM.
If you need to re-run the table as new versions come out, the Python script is also in the Gist.