19 Feb 2017
Kansas City, we have a problem.

A year after roll-out, the Island Health electronic health record (EHR) project being piloted at Nanaimo Regional General Hospital (NRGH) is abandoning electronic processes and returning to pen and paper. An alert reader forwarded me this note from the Island Health CEO, sent out Friday afternoon:
The Nanaimo Medical Staff Association Executive has requested that the CPOE tools be suspended while improvements are made. An Island Health Board meeting was held yesterday to discuss the path forward. The Board and Executive take the concerns raised by the Medical Staff Association seriously, and recognize the need to have the commitment and confidence of the physician community in using advanced EHR tools such as CPE. We will engage the NRGH physicians and staff on a plan to start taking steps to cease use of the CPOE tools and associated processes. Any plan will be implemented in a safe and thoughtful way with patient care and safety as a focus.
– Dr. Brendan Carr to all Staff/Physicians at Nanaimo Regional General Hospital
This extremely expensive back-tracking comes after a year of struggles between the Health Authority and the staff and physicians at NRGH.
After two years of development and testing, the system was rolled out on March 19, 2016. Within a couple months, staff had moved beyond internal griping to griping to the media and attempting to force changes through bad publicity.
Doctors at Nanaimo Regional Hospital say a new paperless health record system isn’t getting any easier to use.
They say the system is cumbersome, prone to inputting errors, and has led to problems with medication orders.
“There continue to be reports daily of problems that are identified,” said Dr. David Forrest, president of the Medical Staff Association at the hospital.
– CBC News, July 7, 2016
Some of the early problems were undoubtedly of the “critical fault between chair and keyboard” variety – any new information interface quickly exposes how much we use our mental muscle memory to navigate both computer interfaces and paper forms.

So naturally, the Health Authority stuck to their guns, hoping to wait out the learning process. Unfortunately for them, the system appears to have been so poorly put together that no amount of user acclimatization can save it in the current form.
An independent review of the system in November 2016 has turned up not just user learning issues, but critical functional deficiencies:
- High doses of medication can be ordered and could be administered. Using processes available to any user, a prescriber can inadvertently write an order for an unsafe dose of a medication.
- Multiple orders for high-risk medications remain active on the medication administration record resulting in the possibility of unintended overdosing.
- The IHealth system makes extensive use of small font sizes, long lists of items in drop-down menus and lacks filtering for some lists. The information display is dense making it hard to read and navigate.
- End users report that challenges commonly occur with: system responsiveness, log-in when changing computers, unexplained screen freezes and bar code reader connectivity
- PharmaNet integration is not effective and adds to the burden of medication reconciliation.
The Health Authority committed to address the concerns of the report, but evidently the hospital staff felt they could no longer risk patient health while waiting for the improvements to land. Hence a very expensive back-track to paper processes, and then another expensive roll-out process in the future.
This set-back will undoubtedly cost millions. The EHR roll-out was supposed to proceed smoothly from NRGH to the rest of the facilities in Island Health before the end of 2016.
This new functionality will first be implemented at the NRGH core campus, Dufferin Place and Oceanside Urgent Care on March 19, 2016. The remaining community sites and programs in Geography 2 and all of Geography 1 will follow approximately 6 months later. The rest of Island Health (Geographies 3 and 4) will go-live roughly 3 to 6 months after that.
Clearly that schedule is no longer operative.
The failure of this particular system is deeply worrying because it is a failure on the part of a vendor, Cerner, that is now the primary provider of EHR technology to the BC health system.

When the IBM-led EHR project at PHSA and Coastal Health was “reset” (after spending $72M) by Minister Terry Lake in 2015, the government fired IBM and turned to a vendor they hoped would be more reliable: EHR software maker Cerner.
Cerner was already leading the Island Health project, which at that point (mid-2015) was apparently heading to a successful on-time roll-out in Nanaimo. They seemed like a safe bet. They had more direct experience with the EHR software, since they wrote it. They were a health specialist firm, not a consulting generalist firm.
For all my concerns about failures in enterprise IT, I would have bet on Cerner turning out a successful if very, very, very costly system. There’s a lot of strength in having relevant domain experience: it provides focus and a deep store of best practices to fall back on. And as a specialist in EHR, a failed EHR project will injure Cerner’s reputation in ways a single failed project will barely dent IBM’s clout.
There will be a lot of finger-pointing and blame shifting going on at Island Health and the Ministry over the next few months. The government should not be afraid to point fingers at Cerner and force them to cough up some dollars for this failure. If Cerner doesn’t want to wear this failure, if they want to be seen as a true “partner” in this project, they need to buck up.
Cerner will want to blame the end users. But when data entry takes twice as long as paper processes, that’s not end users’ fault. When screens are built with piles of non-relevant fields, and poor layouts, that’s not end users’ fault. When systems are slow or unreliable, that’s not end users’ fault.
Congratulations British Columbia, on your latest non-working enterprise IT project. The only solace I can provide is that eventually it will probably work, albeit some years later and at several times the price you might have considered “reasonable”.
11 Feb 2017
“You may find yourself,
In a beautiful house,
With a beautiful wife.
You may ask yourself,
well, how did I get here?”
– David Byrne, Once In a Lifetime
I’ve spilled a lot of electrons over the last 5 years talking about IT failures in the BC government (ICM, BCeSIS, NRPP, CloudBC), and a recurring theme in the comments is “how did this happen?” and “are we special or does everybody do this?”
The answer is nothing more sophisticated than “big projects tend to fail”, usually because more people on an IT project just adds to organizational churn: more reporting, more planning, more reviewing of same, all undertaken by the most expensive managerial resources.
That being so, why do we keep approving and attempting big IT projects? BC isn’t unique in doing so, though we have our own organizational tale to tell.
Both the social services Integrated Case Management (2009) and the Natural Resources Permitting Project (2013) projects were born out of “transformation” intiatives, attempts to restructure the business of a Ministry around new principles of authority and information flow.
Even for businesses as structured and regimented as a Department of Motor Vehicles, these projects can be risky. For a Ministry like Children & Families, where the stakes are children’s lives, and the evaluations of the facts of cases are necessarily subjective, the risk levels are even higher.
Nonetheless, in the mid 2000’s, the Province gave the Ministry of Management Services a new mission, to “champion the transformation of government service delivery to respond to the everyday needs of citizens, businesses and the public sector.” In particular, the IT folks in the Chief Information Officer’s department took this mission in hand. This may be a clue as to why IT projects became the central pivot for “transformation” initiatives.
Around the same time, the term “citizen centred service delivery” began to show up in Ministry Service Plans. Ministries were encouraged to pursue this new goal, with the assistance of Management Services (later renamed Citizens’ Services). This activity reached a climax in 2010, with the release of Citizens @ The Centre: B.C. Government 2.0 by then Deputy to the Premier Alan Seckel.
The “government 2.0” bit is a direct echo of hype from south of the border, where in 2009 meme-machine Tim O’Reilly kicked off a series of conferences and articles on “Government 2.0” as a counterpart to his “web 2.0” meme.
Enthusiasm for technology-driven “government as a platform” resulted in some positive side effects, such as the “open data” movement, and the creation of alternative in-sourced delivery organizations, like the UK Government Digital Service and the American 18F organization in the General Service Administration. In BC the technology mania also wafted over the top levels of civil service, resulting in the Citizens @ The Centre plan.
As a result, the IT inmates took over the asylum. Otherwise sane Ministries were directed to produce “Transformation and Technology Plans” to demonstrate their alignment with the goals of “Citizens @ the Centre”. Education, Transportation, Natural Resources and presumbly all the rest produced these plans during what turned out to be the final years of Premier Gordon Campbell’s rule.
The 2011 change in leadership from Gordon Campbell’s technocratic approach to the “politics über alles” style of Christie Clark has not substantially reduced the momentum of IT-driven transformation projects.
Part of this may be a matter of senior leadership personalities: the current Deputy to the Premier, Kim Henderson was leading Citizen’s Services when it produced Citizens @ The Centre; the former CIO Dave Nikolejsin, an architect of the catastrophic ICM project, remains involved in the ongoing NRPP transformation project, despite his new perch in the Ministry of Natural Gas Development.
Ballooning Budgets
The IT-led do-goodism of “transformation” explains to some extent how systems became the organizing principle for these disruptive projects, but it doesn’t fully explain their awesome size. Within my own professional memory, only 15 years ago, $10M was an surprisingly large IT opportunity in BC. Now I can name half a dozen projects that have exceeded $100M.
The social services Integrated Case Management project provides an interesting study in how a budget can blow up.
“Integrated Case Management” as a desirable concept was suggested by the 1996 Gove Report, (yes, 1996) leading to an “Integrated Case Management Policy” in 1998, and by 1999 a Ministry working group examining “off-the-shelf” (COTS) technology solutions. The COTS review did not turn up a suitable solution, and the Ministry buried itself in a long “requirements gathering” process, culminating in a working prototype by 2002. In 2003, an RFP was issued to expand the prototype into a pilot for a few hundred users.
The 2003 contract to build out the pilot was awarded to GDS & Associates Systems in the amount of $142,800. No, I didn’t drop any zeroes. Six years before a $180,000,000 ICM contract was awarded to Deloitte, the Ministry thought a working pilot could be developed for 1/1000 of the cost.
What happened after that is a bit of a mystery. Presumably the pilot process failed in some way (would love to know! leave a comment! send an email!) because in 2007 the government was back with a Request to procure a “commercial off-the-shelf” integrated case management solution.
This was the big kahuna. Instead of piloting a small solution and incrementally rolling out, the government already had plans to roll the solution out to over 5000 government workers and potentially 12000 contractors. And the process was going to be incredibly easy:
- Phase 1: Procure Software
- Phase 2: Planning and Systems Integration
- Phase 3: Blueprint and Configure
- Phase 4: Implementation
- Phase 5: Future Implementation
Here’s where things get confusing. Despite using “off-the-shelf” software to avoid software development risks, and having a simple plan to just “configure” the software and roll it out, the new project was tied to a capital plan for $180M dollars, 1000 times the budget of the custom pilot software from a few years earlier.
Why?
Whereas the original pilot aimed to provide a new case management solution, full stop, the new project seems to have been designed to “boil the ocean”, touching and replacing hundreds of systems throughout the Ministry.
At this point the psychology of capital financing and government approvals starts to come into play. Capital financing can be hard to get. Large plans must be written and costed, and business cases built to show “return on investment” to Treasury Board.
One way to gain easy “return” is to take all the legacy systems in the organization, fluff up their annual operating costs as much as possible, bundle them together and say “we’re going to replace all this, for an annual savings of $X, which in conjunction with efficiencies $Y from our new technology and centralized maintenance gives us a positive ROI!”
I’m pretty sure this psychology applies, since almost exactly the same arguments backstop the “business case” for the ongoing Natural Resource Permitting Project.
A natural effect of bundling multiple system integrations is to blow up the budget size. This is actually a Good Thing (tm) from the point of view of technology managers, since it provides some excellent resumé points: “procured and managed 9-digit public IT project.”
A manager who successfully delivers a superb $4M IT project gets a celebratory dinner at the pub; a manager who brings even a terrible $140M IT project to “completion” can write her ticket in IT consulting.
The only downside of huge IT projects is that they fail to provide value to end-users a majority of the time, and of course they soak the taxpayers (or shareholders in the case of private sector IT failures, which happen all the time) for far more money than they should.
Can We Stop? Should We?
We really should stop. The source of the problems are pretty clear: overly large projects, and heavily outsourced IT.
Even the folks at the very top can see the problem and describe it, if they have the guts.
David Freud, former Conservative minister at the UK Department for Work and Pensions, was in charge of “Universal Credit” a large social services transformation project, which included a large poorly-built IT component – a project similar in scope to our ICM. He had this to say in a debrief about what he learned in the process:
The implementation was harder than I had expected. Maybe that was my own naivety. What I didn’t know, and I don’t think anyone knew, was how bad a mistake it had been for all of government to have sent out their IT.
It happened in the 1990s and early 2000s. You went to these big firms to build your IT. I think that was a most fundamental mistake, right across government and probably across government in the western world…
We talk about IT as something separate but it isn’t. It is part of your operating system. It’s a tool within a much better system. If you get rid of it, and lose control of it, you don’t know how to build these systems.
So we had an IT department but it was actually an IT commissioning department. It didn’t know how to do the IT.
What we actually discovered through the (UC) process was that you had to bring the IT back on board. The department has been rebuilding itself in order to do that. That is a massive job.
The solution will be difficult, because it will involve re-building internal IT skills in the public service, a work environment that is drastically less flexible and rewarding than the one on offer from the private sector. However, what the public service has going for it is a mission. Public service is about, well, “public service”. And IT workers are the same as anyone else in wanting their work to have value, to help people, and to do good.
The best minds of my generation are thinking about how to make people click ads.
– Jeffrey Hammerbacher
When the Obamacare healthcare.gov site, built by Canadian enterprise IT consultant CGI, cratered shortly after launch, it was customer-focused IT experts from Silicon Valley and elsewhere who sprang into action to rescue it. And when they were done, many of them stayed on, founding the US Digital Service to bring modern technology practices into the government. They’re paid less, and their offices aren’t as swank, but they have a mission, beyond driving profit to shareholders, and that’s a motivating thing.
Government can build up a new IT workforce, and start building smaller projects, faster, and stop boiling the ocean, but they have to want to do it first. That’ll take some leadership, at the political level as well as in the civil service. IT revitalization is not a partisan thing, but neither is it an easy thing, or a sexy thing, so it’ll take a politician with some guts to make it a priority.
11 Dec 2016

While I know full well that Amazon’s marketing department doesn’t need my help, I cannot resist flagging this new development from the elves in Santa’s AWS workshop:
Today we are launching a preview of Amazon Aurora PostgreSQL-Compatible Edition. It offers … high durability, high availability, and the ability to quickly create and deploy read replicas. Here are some of the things you will love about it:
Performance – Aurora delivers up to 2x the performance of PostgreSQL running in traditional environments.
Compatibility – Aurora is fully compatible with the open source version of PostgreSQL (version 9.6.1). On the stored procedure side, we are planning to support Perl, pgSQL, Tcl, and JavaScript (via the V8 JavaScript engine). We are also planning to support all of the PostgreSQL features and extensions that are supported in Amazon RDS for PostgreSQL.
Cloud Native – Aurora takes full advantage of the fact that it is running within AWS.
The language Amazon uses around Aurora is really wierd – they talk about “MySQL compatibility” and “PostgreSQL compatibility”. At an extreme, one might interpret that to mean that Aurora is a net-new database providing wire- and function-level compatibility to the target databases. However, in the PostgreSQL case, the fact that they are additionally supporting PostGIS, the server-side languages, really the whole database environment, hints strongly that most of the code is actually PostgreSQL code.
There is not a lot of reference material about what’s going on behind the scenes, but this talk from re:Invent shows that most of the action is in the storage layer. For MySQL, since storage back-ends are pluggable, it’s possible that AWS has added their own back-end. Alternately, they may be running a hacked up version of the InnoDB engine.
For PostgreSQL, with only one storage back-end, it’s pretty much a foregone conclusion that AWS have taken a fork and added some secret sauce to it. However, the fact that they are tracking the community version almost exactly (they currently offer 9.6.1) indicates that maybe their fork isn’t particularly invasive.
I’d want to wait a while before trusting a production system of record to Aurora PgSQL, but the idea of the cloud native PostgreSQL, with full PostGIS support, excites me to no end. RDS is already very very convenient, so RDS-with-better-performance and integration is just icing on the cake for me.
I, for one, welcome our new cloud database overlords.
06 Dec 2016
Hey, good news zombie lovers, the project I’ve declared dead (or, at least, doomed) is not only still shambling around, it’s going to get the official political glad-handing treatment tomorrow:

We are excited to share an important Natural Resource Permitting Project (NRPP) milestone. Tomorrow—December 7—NRPP’s first service on the NRS Online Services website will be launched in Williams Lake at FrontCounter BC with Minister of State for Rural Economic Development Donna Barnett.
I always feel sad for the poor politician tasked with the “new website” announcement, because honestly, is there any announcement that feels like more of an empty gesture towards real action? “Yes, I understand you wanted $50M for addiction treatment, but… how about this new web site?”
Anyways, while she’s getting her demonstration of the new NRS Online Services website, here’s some questions Minister Barnett might like to ask:
- Can I drive? Let me use the computer. Why don’t you ever let the Minister use the computer? I’m the Minister, dammit.
- Why is it so slow? Surely for this kind of money it should be fast.
- What are all those buttons across the top? What does the pencil mean? I’ve never seen those icons before. What do you mean “have I ever used ArcView?”, what’s ArcView?
- You really expect me to click all those links to find out what impacts my project? There’s got to 20 of them!
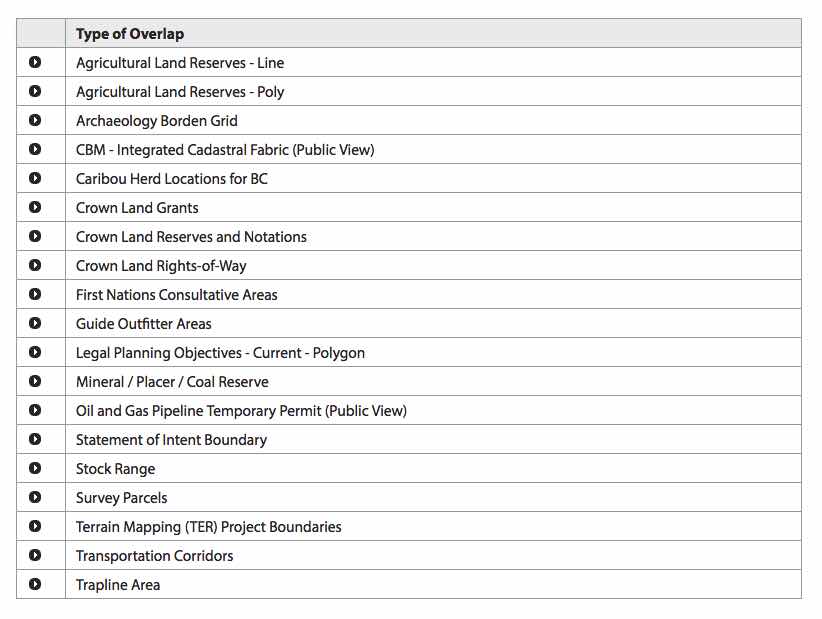
- Does it work on my phone? Ah, kind of, I see. No, I don’t know what a “bootstrap” is.

- Honestly, why is it so slow? Am I clicking it wrong?
- Does this work align with government priorities? Maybe you need to do some more transformation on it.
Congratulations, NRPP on your first step towards transforming the sector, have a great demo!
Addendum: In the press release, Minister Steve Thomson is quoted as “saying” (poor Ministers always sound so stodgy when they “speak” in press releases):
Through the Natural Resource Permitting Project, the Province is making a significant investment in helping communities balance economic development with protecting our natural resources.
My notes:
- The province is surely making a “significant investment” in Deloitte and CGI. Whether that investment ends up “helping communities” is still very much a question in flux.
- The purpose of NRPP is not “balance” between economic development and protected natural resources. The business case makes clear, the purpose of NRPP is to increase natural resource extraction rates, generating a permanent lift in royalties to offset the (significant) costs of NRPP. Sadly, even on those terms it’s likely to fail.
Such a short sentence, yet still so much misdirection.
04 Dec 2016
I have found it extremely difficult to extract information about NRPP from the government. FOIs have come with very large fee assessments, or documents have been completely redacted – you’d think I was out to get them or something.

New flash: I am not out to get them. In fact, they are the best-run IT mega-project I’ve seen so far in the BC government. But that doesn’t change the fact that, like the dinosaurs before them, they are doomed, dooooomed.
Fortunately, the FOI process can be indiscriminate, information can leak out despite the best efforts of the project team, and last month there was great tidbit about NRPP.
Hiding inside an FOI request to the Environmental Assessment Office (EAO) were a number of interesting documents.
Who’s On First?
In an email on June 24, 2016, Wilf Bangert, the Assistant Deputy Minister (ADM) for NRPP, invited the steering committee of ADMs to a meeting to:
define the meaning of ‘sector transformation’ by documenting a model that will enable its implementation.
Or put another way, after three years and $50M, the “Natural Resources Sector Transformation Secretariat” (NRSTS) still isn’t clear on what “transformation” means, and is looking for guidance.
It’s not too hard to figure out what’s going on.
Lacking any operational mandate themselves, NRSTS has been going around looking for partners with operational permitting processes: “come work with us, we’ll re-structure your business work-flow and make it ‘better’ with cool software we haven’t built yet”.
To me, this sounds good (cool software! better!); to NRSTS, this sounds good (re-structure!); to the permitters it sounds like “we’re going to waste a bunch of your (scarce) time in workshops making you talk about abstractions instead of doing your job, then we’re going to upend your office in the service of ‘transformation’, while we experiment with software that is as yet unwritten”.
You know what happened to the guy who had the first human heart transplant? In IT terms, the procedure was a success – he didn’t die on the table. He died 18 days later of pneumonia, with his heart still pumping away.
Back to High School
After asking for advice on ‘transformation’ from the ADMs, Bangert then tells them he needs a “subject matter expert” (at a “decision making level”!) from each of them to attend “several” workshops in the summer and a week-long workshop in the fall. So, presumably a manager or director, whose time is sufficently low value that it can be donated to NRSTS for days at a time.

But that’s not even the best part. The best part is the structure of that five-day fall workshop. NRPP is going to be running (has already run?) a “Model UN” process with all these managers and directors.
My favourite bullet points! From the “How Will it Work” section:
- An unlimited number of delegates are allowed per Ministry. Attendance and pre-work completion is mandatory before and for the duration of the workshop.
Because more is better, and mandatory homework makes fast friends! From “Who Should Attend”
- Folks who are highly motivated to make the Natural Resources Sector “processes” work better.
- Extroverted communicators and people connectors.
- Introverted thought leaders and thinkers.
- Creative problem solvers.
Great combination! Anyone not invited?
Still, so far we’re just talking about a standard “consultant-facilitated workshop time vortex”, of a sort we’ve all participated in and/or inflicted on others. The bit that is really transcendent is the “engagement model UN process”:
- There is a general assembly component
- Only voting delegates attend
- Voting on resolutions prepared by committees
- Decision making body for the process
- Mandatory that voting delegate attends
- Fixed time for debate and voting
- A chairperson oversees
- Process repeats [emphasis added] until all aspects of the work flow have been reviewed, resolution prepared, and voted on.
How could this possibly go wrong?!?
The Smell of Desperation
Once again, inputs:
Outputs:
- “What exactly do you mean by ‘transformation’, really?”
- “Lend us your SME’s for a week, so we can figure out a generic process to stuff your business into.”
- Also, some unimpressive deliverables.

If a core early problem with NRSTS was that nobody wanted to be the first organization to be subjected to their tender mercies, imagine how they are perceived now, as they come up on the end of their Phase 1 funding and still haven’t even figured out what “transformation” means?
Would you trust your staff time and business process to an organization that looks likely to be blown up in the next 24 months? If so, why?
Addendum: Commenters, please weigh in on whether the recent departure of the Executive Director, Technology to work with major project consultant CGI is (a) a sign of good things to come (CGI positioning to win follow-on work in Phase Two) or (b) a sign of imminent disaster (man-in-the-know getting out while the getting is good).




{kind=link}